 Skip to main content
Skip to main content

In this article, we’ll consider Dynamic Disks. We are going to explore the program implementation with the help of the LDM (Logical Disk Manager) technology.
Contents:
Written by:
Andrey Bisikalo,
Software Designer
Introduction
This article will be useful for those who study the structure of hard disk drives, develop utilities for changing this structure, or for people who deal with other questions related to the structure of hard disk drives such as backup, data recovery, or information extraction.
First of all, we will observe the basis: what a dynamic disk is and how it differs from a common disk. In addition, we will explore the types of dynamic volumes, their pros and cons.
The next section deals with the inner structure of dynamic disks: what disks and volumes consist of, how they are connected with each other, where this structure is stored and how to process it properly.
Based on knowledge of the structure of dynamic disks, a parser is implemented. The third section describes this parser. The implemented parser is cross-platform.
Dynamic Disks: Basics
Let’s start from the terminology.
Disk — a hard disk drive connected to the system. Each disk can contain one, several, or no partitions.
Partition — a hard disk drive’s unit, which is interpreted by the operating system as a single whole for usability.
Volume —a set of partitions, which is interpreted by the system as a single logic disk with a file system. A volume can consist of one or several partitions.
Existing Types of Disks. Difference Between Dynamic Disks and Basic Disks
Disks can be basic and dynamic.
Basic disks have a simple logic structure: a hard disk drive is divided into several partitions with the help of the partition table. Each partition is a logic disk, in other words, a volume always consists of one partition. This means that one volume can be physically located only on one disk. In order to increase or decrease the size of a volume, the size of a partition related to this volume has to be changed.
Dynamic disks have a more complicated logic structure: a volume can consist of one or several partitions located on one or several disks. In order to increase or decrease the size of a volume, one can change the size of a partition related to this volume or add new or delete existing partition.
In comparison with basic volumes, dynamic volumes have the following specifics of usage (depending on the type of a volume):
- possibility to increase the size of a volume by means of additional hard disk drives;
- performance improvement by means of paralleling of recording to several hard disk drives;
- increased reliability due to redundancy; the failure of one drive will not cause the loss of data.
Types of Dynamic Volumes
Let’s find out more about types of dynamic volumes and their characteristics. There are the following types of dynamic volumes:
- Simple. It is an analogue of the simple volume on a basic disk. As a rule it consists of one partition. It can also include several partitions, but all partitions of this volume have to be located on one disk. It doesn’t differ from basic volumes in its reliability, redundancy, or performance. The simple volume has no analogues in RAID arrays.
- Spanned. It consists of several partitions, located on different disks. In comparison with basic volumes, it enables creating volumes of large sizes, combining the space of several disks together. It doesn’t differ from basic volumes in its reliability, redundancy, or performance. The spanned volume has no analogues in RAID arrays.
- Striped. It is the spanned volume analogue; the only difference is the recording method: data is divided into blocks, and blocks are recorded on disks simultaneously. In other words, the first block is recorded on the first disk, the second block is recorded on the second disk, and so on. The reliability is low because failure of one disk causes the loss of all data. There is no redundancy. The performance is pretty high because of operation paralleling. The striped volume is the RAID-0 array analogue.
- Mirrored. It consists of two partitions on different disks. Partitions are exact copies of each other, meaning that data is being duplicated. The reliability is high, in case of failure of one disk, data can be received from the second disk. The redundancy is high as well: since data is being duplicated into two partitions, the number of useful space is 50% from the total. The performance is lower than performance of other types of volumes. The mirrored volume is the RAID-1 array analogue.
- RAID-5. It consists of 3 or more partitions located on different disks. Operations with volume are being paralleled, giving a small increase in performance. One of the partitions is used for storage of correction codes. The reliability is high because in case of failure of one disk data can be restored with the help of correction codes. The redundancy is lower than the redundancy of the mirrored volume, the number of useful space depends on the number of disks. The performance is pretty high because of operation paralleling . The RAID-5 volume is the RAID-5 array analogue.
Dynamic Disks Internals
All information about the structure of dynamic disks is stored in the LDM database. The LDM database has one copy for each hard disk drive. In order to find the database, we must consider the used table of disk partitions.
In case of MBR, the dynamic disk will have only one partition with the size of the whole disk. The type of this partition has to be 0х42, meaning the logical disk manager partition. And the LDM database is stored in the last megabyte of the hard disk drive.
First of all, it should be mentioned that all data of the LDM database is stored in the big-endian format that is why while using the LDM data, the ByteReverse function is applied.
The first LDM structure that we see is a private head (PRIVHEAD). It is located by the 0xC00 offset , not the 0x200 one, despite the statements in references. ([1], [2]).
PRIVHEAD has the following appearance:
struct PrivHead
{
uint8_t magic[8];
uint32_t checksum;
uint16_t major;
uint16_t minor;
uint64_t timestamp;
uint64_t sequenceNumber;
uint64_t primaryPrivateHeaderLBA;
uint64_t secondaryPrivateHeaderLBA;
uint8_t diskId[64];
uint8_t hostId[64];
uint8_t diskGroupId[64];
uint8_t diskGroupName[31];
uint32_t bytesPerBlock;
uint32_t privateHeaderFlags;
uint16_t publicRegionSliceNumber;
uint16_t privateRegionSliceNumber;
uint64_t publicRegionStart;
uint64_t publicRegionSize;
uint64_t privateRegionStart;
uint64_t privateRegionSize;
uint64_t primaryTocLba;
uint64_t secondaryTocLba;
uint32_t numberOfConfigs;
uint32_t numberOfLogs;
uint64_t configSize;
uint64_t logSize;
uint8_t diskSignature[4];
Guid diskSetGuid;
Guid diskSetGuidDupicate;
};As we can see, PRIVHEAD includes the general information about database. We are particularly interested in these two fields:
privateRegionStart– the LDM database offset (private region). We must calculate the offsets of other structures in LDM starting from this offset.primaryTocLba– The table of contents (TOC) offset relative to the private region.
uint64_t TocOffset(const PrivHead* privhead, PhysicalDisk& drive)
{
uint64_t privateRegion = ByteReverse(privhead->privateRegionStart);
uint64_t tocOffset = ByteReverse(privhead->primaryTocLba);
return (privateRegion + tocOffset) * drive.SectorSize();
}TOCBLOCK contains information about the LDM features. It has the following structure:
struct TocRegion
{
uint8_t name[8];
uint16_t flags;
uint64_t start;
uint64_t size;
uint16_t unk1;
uint16_t copyNumber;
uint8_t zeroes[4];
};
struct TocBlock
{
uint8_t magic[8];
uint32_t checksum;
uint64_t updateSequenceNumber;
uint8_t zeroes[16];
TocRegion config;
TocRegion log;
};As we can see, TOCBLOCK includes description of two sections – config and log. The first section contains the part of the database we need.
uint64_t VmdbOffset(const PrivHead* privhead, const TocBlock* tocblock, PhysicalDisk& drive)
{
uint64_t privateRegion = ByteReverse(privhead->privateRegionStart);
uint64_t configOffset = ByteReverse(tocblock->config.start);
return (privateRegion + configOffset) * drive.SectorSize();
}If we jump by the offset mentioned in the config section (relative to the private region), the next LDM structure, VMDB, appears. VMDB is the header of the VBLK list.
struct Vmdb
{
uint8_t magic[4];
uint32_t sequenceNumberOfLastVblk;
uint32_t sizeOfVblk;
uint32_t firstVblkOffset;
uint16_t updateStatus;
uint16_t major;
uint16_t minor;
uint8_t diskGroupName[31];
uint8_t diskGroupGuid[64];
uint64_t committedSequence;
uint64_t pendingSequence;
uint32_t numberofCommittedVolumeBlocks;
uint32_t numberOfCommittedComponentBlocks;
uint32_t numberOfCommittedPartitionBlocks;
uint32_t numberOfCommittedDiskBlocks;
uint32_t numberOfCommittedDiskAccessRecords;
uint32_t unused1;
uint32_t unused2;
uint32_t numberOfPendingVolumeBlocks;
uint32_t numberOfPendingComponentBlocks;
uint32_t numberOfPendingPartitionBlocks;
uint32_t numberOfPendingDiskBlocks;
uint32_t numberOfPendingDiskAccessRecords;
uint32_t unused3;
uint32_t unused4;
//uint8_t zeroes[16]; VSFW 4.0 adds this field upon installation, and removes it during unsinstall, it is unclear how to detect if this field will appear or not, other than checking 0xCD to see if it's in use.
uint64_t lastAccessTime;
};We are interested in the offset of the first element, element size and the number of the last element. VBLK are numbered starting from 4, that’s why as a rule the offset of the first element is 512 and the size is 128. VMDB occupies VBLK numbers from 0 to 3.
uint64_t FirstVblkOffset(
const PrivHead* privhead, const TocBlock* tocblock, const Vmdb* vmdb, PhysicalDisk& drive)
{
return VmdbOffset(privhead, tocblock, drive) + ByteReverse(vmdb->firstVblkOffset);
}VBLK is an element of the database that represents one of the objects (volume, component, partition, disk, disk group). In order to understand the purpose of each object, let’s explore the structure of each one.
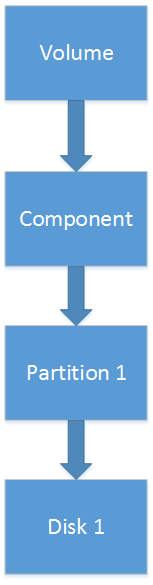
- The simple volume consists of one component, one or several partitions, each of partitions refers to the same disk.
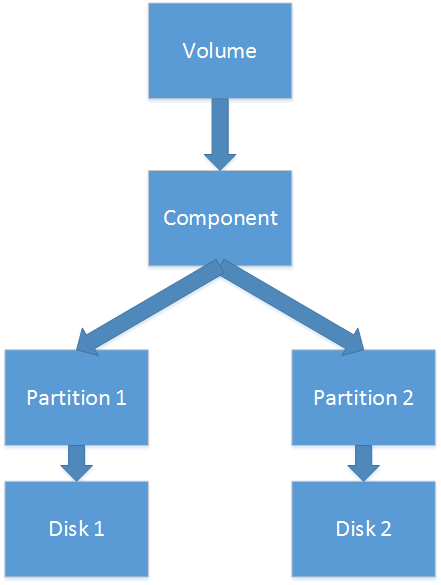
- The spanned and striped volumes consist of one component, one or several partitions that refer to different disks.
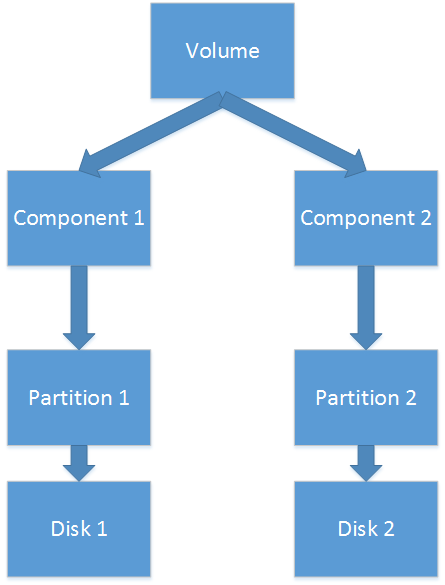
- The mirrored volume consists of two components, the data on which is being duplicated. Each component has one partition, and partitions refer to two different disks.
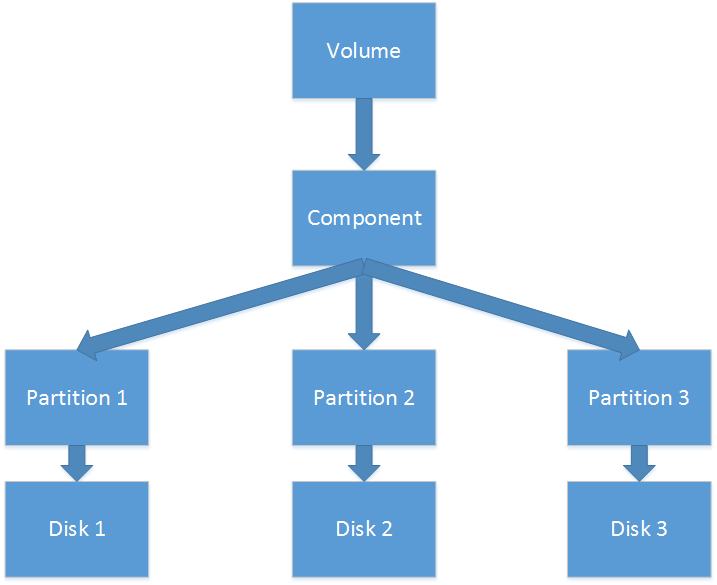
- The RAID-5 volume consists of one component; the component has three or more partitions that refer to different disks.
As we can see, in theory such architecture of volumes could support more complicated volume types. For instance, the mirrored-spanned volume would have the following appearance:
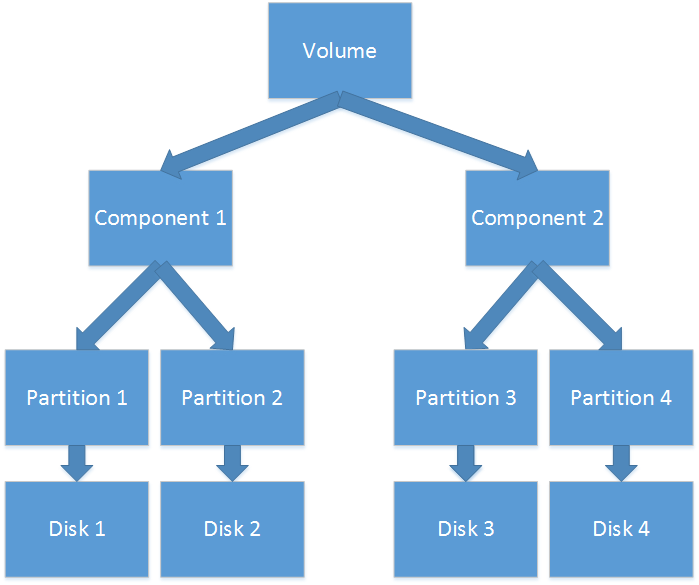
But in practice, such types of volumes are not supported: neither Windows Disk Management nor 3rd party utilities for work with disks are able to create such volume. After an attempt to create such volume manually, Windows refused to work with group of disks and marked them with the Invalid status.
The VBLK content differs depending on the type of the component it represents. But all VBLKs have a common standard header that determines the number of VBLK, the group number, the quantity of fragments, and the number of a fragment.
If data are too large to be stored in a single VBLK, the rest of data is recorded to another VBLK structure. Such structures are connected with a single group number.
In all types of VBLK, cell status, flags, cell type, and content length are stored after the standard header.
struct VblkHeader
{
uint8_t magic[4];
uint32_t sequenceNumber;
uint32_t groupNumber;
uint16_t recordNumber;
uint16_t numberOfRecords;
};
struct ExtendedVblk
{
VblkHeader header;
uint16_t updateStatus;
uint8_t flags;
uint8_t type;
uint32_t length;
uint8_t otherData;
};Let’s explore each type of the VBLK cell. It should be mentioned that to each object has unique ID. Connections inside the LDM base are created using Object IDs.
Many fields in VBLK have a variable size. The first byte of such field stores the size of data, and then data of specified size is located. Such fields are marked with the var prefix.
- Volume
struct VolumeVblk //pseudocode
{
var_uint64_t objectId;
var_string name;
var_string type;
var_string disableDriveLetterAssignment;
int8_t state[14];
int8_t readPolicy;
var_uint64_t volumeNumber;
uint32_t flags;
var_uint64_t numberOfComponents;
uint64_t commitTransactionId;
uint64_t unknownTransactionId;
var_uint64_t size;
uint8_t zeroes[4];
uint8_t partitionType;
Guid guid;
var_uint64_t id1; //exists if vblk flags contain 0x08
var_uint64_t id2; //exists if vblk flags contain 0x20
var_uint64_t columnSizeLba; //exists if vblk flags contain 0x80
var_string mountHint; //exists if vblk flags contain 0x02
};We can get the following information from this: a disk letter (if it is assigned), a volume size, and used file system.
The field type can have two values, gen and raid5. This field only shows us whether it is RAID-5 volume or not.
- Component
struct ComponentVblk //pseudocode
{
var_uint64_t objectId;
var_string name;
var_string state;
uint8_t layout;
uint32_t flags;
var_uint64_t numberOfPartitions;
uint64_t commitTransactionId;
uint64_t zero;
var_uint64_t volumeId;
var_uint64_t logsd;
var_uint64_t stripeSizeLba; //exists if vblk flags contain 0x10
var_uint64_t numberOfColumns; //exists if vblk flags contain 0x10
};We can get the following information from this: volume type from the partitionLayout field (stripe, concatenated, RAID-5), partitions quantity, volume id to which the component belongs. For the stripe and raid volumes we can also get the size of the stripe.
- Partition
struct PartitionVblk //pseudocode
{
var_uint64_t objectId;
var_string name;
uint32_t flags;
uint64_t commitTransactionId;
uint64_t diskOffsetLba;
uint64_t partitionOffsetInColumnLba;
var_uint64_t sizeLba;
var_uint64_t componentId;
var_uint64_t diskId;
var_uint64_t columnIndex; //exists if vblk flags contain 0x08
var_uint64_t hiddenSectorsCount; //exists if vblk flags contain 0x02
};We can get the following information from this: offset on the disk (relative to the public region), offset in the volume (if the volume is simple or spanned), the size of partition, component ID and disk ID, to which partition belongs.
- Disk
struct Disk1Vblk //pseudocode
{
var_uint64_t objectId;
var_string name;
var_string guid;
var_string lastDeviceName;
uint32_t flags;
uint64_t commitTransactionId;
};struct Disk2Vblk //pseudocode
{
var_uint64_t objectId;
var_string name;
Guid guid;
Guid diskSetGuid;
var_string lastDeviceName;
uint32_t flags;
uint64_t commitTransactionId;
}; From this structure we can get GUID of the disk, which is also stored in the PRIVHEAD structure. It can be also used to associate a disk, described by the VBLK structure, with a physical disk.
- Disk group
struct DiskGroup1Vblk //pseudocode
{
var_uint64_t objectId;
var_string name;
var_string guid;
uint8_t zeroes[4];
uint64_t commitTransactionId;
var_uint64_t numberOfConfigs; //exists if vblk flags contain 0x08
var_uint64_t numberOfLogs; //exists if vblk flags contain 0x08
var_uint64_t minors; //exists if vblk flags contain 0x10
};struct DiskGroup2Vblk //pseudocode
{
var_uint64_t objectId;
var_string name;
Guid guid;
Guid lastDiskSetGuid
uint8_t zeroes[4];
uint64_t commitTransactionId;
var_uint64_t numberOfConfigs; //exists if vblk flags contain 0x08
var_uint64_t numberOfLogs; //exists if vblk flags contain 0x08
var_uint64_t minors; //exists if vblk flags contain 0x10
}; The structure describes the group of disks entirely. We can get a name and GUID of the group from it.
Description of Parser
Now let’s move to the most interesting part – implementation of a parser. The source code of dynamic disks parser is attached to this article.
In order to simplify an example, I made several assumptions during realization. That is why while using a parser we have to take into consideration the following aspects:
- Despite the fact that a parser itself is cross-platform, it processes dynamic disks created with the help of LDM.
- The current version of parser processes dynamic disks only with the MBR partition table. Dynamic disks can use the GPT partition table too. In this case we have to look for the LDM metadata section in which the database will be stored.
- The current version of parser assumes that the most recent LDM database is stored on the first disk, or all disks have the same LDM database. In general, it can be not like this. Such situations like turning off or damage of one or several dynamic disks can cause that databases on disks will differ. That is why the complete database (i.e. all VBLKs) is processed entirely only for the first disk, for the rest of the disks only PRIVHEAD is processed.
- The current version of parser assumes that the LDM database has no mistakes. LDM contains various information to protect the base from mistakes, but this information is not used in parser.
- The current version of parser assumes that the size of VBLK will be so that sector will contain the integer number of VBLK. I met VBLK of the 128 bytes size only so it should not be a problem.
- The current version of parser assumes that all components will fit in a single VBLK structure. If big components have to be processed, we need to stick together data from several VBLK by the group number.
- The current version of parser processes only one case of Disk and Disk group VBLK structures. I met only such cases. If needed, processing of the second case can be added.
- The current version of parser is meant for a little-endian architecture. It has been already mentioned that all data in the LDM database is stored in the big-endian format that is why when using such data I apply the ByteReverse function.
- The Current version of parser uses the 512-byte size of the sector when calculating the volume size. If LDM performs such optimization and stores the volume size in a separate field, then I used it in such a way.
Parser consists of two main classes:
- Parser itself. It reads the LDM structures from a disk.
- VblkParser. It parses the VBLK structures putting the necessary information into containers.
Here how the work with the parser goes:
Parser parser;
for (int i = 0; i < count; ++i)
{
parser.Parse(diskNames[i]);
}
parser.BuildRelations();
const VolumeContainer& volumes = parser.GetVolumes();
const DiskContainer& disks = parser.GetDisks();
//use volumes and disksWe create a parser object, call the parsing function for each dynamic disk, establish connections between them, and the output is the list of the volumes and disks.
Some people may be confused of the BuildRelations function call. It’s a matter of fact that the VBLK structures are stored in the database in unordered way. That is why we cannot establish connections between the components at once neither with direct method (for example, connect the volume with its components in the moment the volume has been read), nor with reverse one (for example, connect the component with the volume in the moment the component has been read) because all the necessary structures for connection could have been not read yet, or not all of them could have been read.
The disk is parsed in the way described in the previous section: read PRIVHEAD, find out the TOCBLOCK offset from it, after that we find VMDB and read all VBLK, extracting all the needed information.
The VBLK parsing is performed quite easy too: by the field “type”, we determine which object of the base represents the given VBLK. After that we read the fields related to this object one by one, and put the objects into containers.
Now let’s find out what kind of information the parser saves.
For the partition the structure stores ID, offset on the disk, partition size, offset in the volume (it is relevant only for the simple and spanned volumes, for the rest it is 0) and disk ID, to which the partition is related. Offset on the disk is absolute (in other words, the public LDM region offset is already included) but it is shown in sectors not in bytes. Offsets and sizes in all structures are shown in sectors.
struct Partition
{
uint64_t id;
uint64_t diskOffsetLba;
uint64_t sizeLba;
uint64_t volumeOffsetLba;
uint64_t diskId;
};The following information is stored for the component: ID, component type, and the list of partitions.
struct Component
{
uint64_t id;
ComponentLayout layout;
PartitionContainer partitions;
};We store the volume ID, volume type, used file system, size, and components.
struct Volume
{
uint64_t id;
VolumeType type;
FsType fileSystem;
uint64_t sizeLba;
ComponentContainer components;
};The stored information for the disk is ID, GUID, path to the disk (this path is taken from the command line parameters), the size of the sector for partition size calculation, public region offset and partitions.
struct Disk
{
uint64_t id;
std::string guid;
std::string path;
uint32_t sectorSize;
uint64_t logicalStartLba;
PartitionContainer partitions;
};Now let’s see in detail how connections are established. During the VBLK parsing connections are read and recorded to the following containers.
typedef std::set<uint64_t> ObjectIdContainer;
typedef std::map<uint64_t, ObjectIdContainer> ObjectToObjectContainer;
ObjectToObjectContainer m_volumeToComponent;
ObjectToObjectContainer m_componentToPartition;
ObjectToObjectContainer m_diskToPartition;It means that a list of components is associated with each volume, a list of partitions is associated with each component and with each disk. And these lists are used for connections establishment.
We should also mention the algorithm for determining the volume type. As there is no field in the LDM that would definitely identify the volume type, the following algorithm is applied:
- If the volume has 2 components, then it is a mirrored volume.
- If it doesn’t have, then the type of the component is examined.
- If the component has the RAID type, then it is a RAID-5 volume.
- If the component has the stripe type, then it is a striped volume.
- If the component has the concatenated type, then it can be a simple or a spanned volume. To determine the type, all partitions of the component are examined.
- If all partitions are related to one disk, then it is a simple volume.
- If partitions are related to different disks, then it is a spanned volume.
After parsing and connections establishment, we can get all the necessary information: volume types, volumes and partitions sizes, location on disk, etc.
Additional utility classes:
- PhysicalDisk. It gives an interface for reading data from a disk.
- ErrnoException. It is an exception, used to notify about problems while accessing a disk.
- Units. It is used for a formatted output of the volumes and partitions sizes.
Parser includes a Visual Studio 2010 solution and makefile to build the project using gcc.
Launching of Parser
An application receives paths to the dynamic disks for the input, and outputs information about dynamic volumes, located on these disks. If some disk is absent in the list, the message “Missing” will be displayed instead of it.
When starting the parser on Windows, paths to disks must be in the following format: .PhysicalDriveX, where X is the dynamic disk number. For example,
LdmParser.exe .PhysicalDrive1 .PhysicalDrive2 .PhysicalDrive3
When starting the parser on Linux, paths to disks must be in the following format: /dev/sdX, where X is an assigned disk letter. For example:
./LdmParser /dev/sdb /dev/sdc /dev/sddConclusion
In this article, we explored the structure of dynamic disks based on the LDM technology. The knowledge of the LDM database structure helps not only in obtaining information about dynamic disks, but also in changing and restoring it.
The code, attached to the article, can be used both on Windows and Linux, which makes it more universal. The result can be used in utilities for work with hard disk drives or in backup systems. In addition, it can be used as a supportive tool for the data restore.
Download Dynamic Disk Parser sources (ZIP, 15 KB)
Useful Links
- The general description of LDM http://en.wikipedia.org/wiki/Logical_Disk_Manager
- LDM’s overview and documentation on its inner structures http://russon.org/ntfs/ldm/
- LDM’s overview and documentation, but it is less precise http://ntfs.com/ldm.htm
- An article dedicated to dynamic disks and volumes http://technet.microsoft.com/en-us/library/cc785638%28v=ws.10%29.aspx
- For those who are not interested in details described in the article, but who are interested in the ways to do the same with the help of API. It works only for Windows http://msdn.microsoft.com/en-us/library/windows/desktop/aa383429%28v=vs.85%29.aspx
- RAID arrays http://en.wikipedia.org/wiki/RAID
Read also: Optimizing SQL Queries


