 Skip to main content
Skip to main content
This article describes a driver that hides processes and files using the method of splicing.
Introduction
This article is a continuation of a set of articles on hiding and detection of files and processes in the operating system. I suppose you have already read articles Driver to Hide Processes and Files and Simple SST Unhooker.
The Simple SST Unhooker article represents the method of solving the problem of substitution of function address in the SST table. In this article, I will describe program methods of hooking functions, which will make the methodology described in the Simple SST Unhooker article do not work.
Introduction to Splicing Basis
In the Driver to Hide Processes and Files article, it is written a lot about why we need the interception of system functions. In this article, I want to focus your attention on the comparison of interception technologies, their advantages and disadvantages.
We can divide the interception methods to the following groups:
- Substitution of the address of the real function (modification of IAT tables, modification of SSDT/IDT tables);
- Direct change of the function (splicing, interception in the kernel mode with the modification of the function body);
- Direct substitution of the whole component of the application/system (for example, substitution of the library with a target function).
We can also divide them by the execution mode in the following way:
- User (ring3) methods: modification of IAT tables, splicing. Their peculiarity is that you cannot change anything in the behavior of OS kernel and its extensions;
- Kernel mode: modification of SSDT/IDT tables, interception in the kernel mode with the modification of the function body. With the help of this, you can modify data structure and the code of any part of OS and applications.
Splicing
Splicing is a method of interception of API functions by changing the code of the target function. Usually, the first 5 bytes of the function are changed. Instead of them, a jump to the function specified by the developer is inserted. To make the operation perform correctly, application that intercepts the function must enable the execution of the code that was changed during splicing. To do this, application saves the part of memory being substituted and after the interception function finishes its work, the application restores the saved function part and enables the real function to be completely executed.
Specifics of the Technology
This technology depends on the platform and that’s why it needs thorough control and check of the system for the correspondence of versions. Also, it needs the check of the function for correspondence with the target one. System functions can change when new patches and Windows updates appear (especially, Service Pack for Windows) and also as a result of modifications by other applications. Errors when working with this technology can cause BSOD. At the same time, this technology helps to perform the global interception of API functions and influences all processes in the system in such way. When hooking SSDT, we get to the redefined function only if it is called through the table of system calls. When using splicing, the function will be called at each call to the original function.
Splicing Scope and Methods of Detection
Splicing is used in the software that should perform the following:
- Functions of system monitoring;
- Mechanism of hooks in Windows;
- Different malicious software. This is the main technology of hiding for the rootkits of the user level.
Project Structure
To make advantages and disadvantages of this technology clearer, I decided not to write the code from the beginning before the substitution of the address in SST. But I decided to make some required changes to the source driver code from the Driver to Hide Processes and Files article so that it could work avoiding SSTUnhooker and was based on the method of splicing.
Changes are made only in the HideDriver project and only in the PrcessHook. This will make it possible to compare two different approaches in one project.
Technical Side
So, how does splicing work from the point of view of the code? To answer this question, we need to refresh our knowledge on agreements of calls of subroutines and on stack.
Call Agreement and Stack
Call agreement defines the following peculiarities of the process of subroutines use:
- Location of input parameters of the subroutine and values returned by it. The most widespread variants are the following:
- In registers;
- In the stack;
- In dynamically allocated memory.
- Order of transfer of parameters. When using stack, it defines in which order parameters should be placed to stack; when using registers, it defines the order of comparison of parameters and registers. Variants are the following:
- Direct order — parameters are placed in the same order as they are enumerated in the subroutine description.
- Reverse order — parameters are passed from the end to the beginning. It simplifies the implementation of subroutines with undefined number of parameters of random types.
- What returns the stack pointer to the initial position:
- Called subroutine — this cuts the number of commands that are required for the call of the subroutine as the commands of the stack pointer recovery are written only once at the end of the subroutine;
- Calling program — in this case, the call becomes more complicated but the use of the subroutines with the variable number and type of parameters becomes easier.
- Which command to use to call the subroutine and which command to use to return to the main program? For example, you can call the subroutine through
call near,call far, andpushf/call far(for the return, useretn,retf,iret, correspondingly) in the standard x86 mode. - Contents of which registers of the processor the subroutine should restore before the return.
Call agreements depend on the architecture of the target machine and the compiler.
In our case, we perform splicing of API. As it is known, it is the __stdcall type. Using this type, arguments are passed through the stack in right-to-left order. The called subroutine performs the stack cleanup.
Stack looks like the following when we are at the very beginning of the function if it has the stdcall call type:
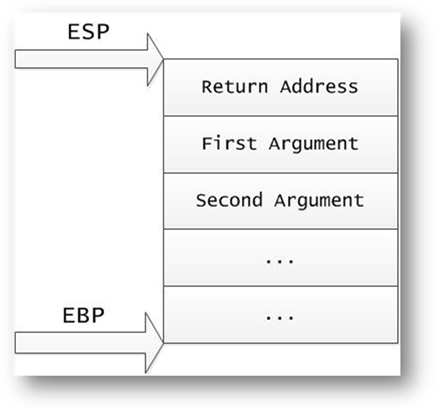
Stack is changed by the assembler call instruction. It transfers the control to the subroutine and writes the return address to the stack. The ret instruction returns the control to the calling side and takes the return address from the stack top.
Code Review
Now, we can prepare the model that will work as follows.
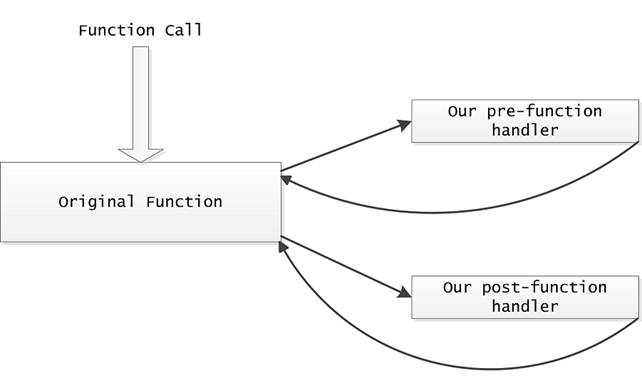
You can view the implementation of this scheme on the example of our driver.
First, we need to declare the handlers themselves. For this, we need to use the following definitions:
#define DEFINE_POST_HANDLER(Name, ImplName,ParamsData)
static void __stdcall ImplName(unsigned long * pRetValue,
ParamsData * pData,
unsigned long dwOldEax);
static __declspec(naked) void __stdcall Name()
{
__asm pushad
__asm push eax
__asm mov eax, [esp+0x28]
__asm push eax
__asm lea eax, [esp+0x28]
__asm push eax
__asm call ImplName
__asm popad
__asm ret 4
}
//-------------------------------------------------------------------------
#define DEFINE_FORE_HANDLER(Name, ImplName)
static void __stdcall ImplName(unsigned long * pFirstData);
static __declspec(naked) void __stdcall Name()
{
__asm pushad
__asm lea eax, [esp+0x28]
__asm push eax
__asm call ImplName
__asm popad
__asm ret
}As we can see, here, stubs for the call of the handlers are declared and, at the same time, all registers are saved in the default state.
Now, let’s look at the function that takes the control at the very beginning of the execution of the original function:
static void __stdcall NtQuerySystemInfo_HookHandlerImpl(unsigned long * pContext)
{
unsigned long * pRetPoint = GET_RET_POINT_PTR(pContext);
struct NtQuerySystemInfo_HookHandler_Data * pParamsData = 0;
void * pStub = 0;
if (AllocatePostParams(&g_kernelNonPagedAllocator,
sizeof(struct NtQuerySystemInfo_HookHandler_Data),
NtQuerySystemInfo_HookHandler_PostHandler,
(void**)&pParamsData,
&pStub)
)
return;
// fill params
pParamsData->dwRealIP = *pRetPoint;
pParamsData->SystemInformationClass = (SYSTEM_INFORMATION_CLASS)GET_PARAM(pContext, 0);
pParamsData->SystemInformation = (PVOID)GET_PARAM(pContext, 1);
pParamsData->SystemInformationLength = GET_PARAM(pContext, 2);
pParamsData->ReturnLength = GET_PARAM_PTR(pContext, 3);
// set new ret point
*pRetPoint = (unsigned long)pStub;
}This function allocates memory for the parameters and creates a stub for the POST_HANDLER call. Next, we save original return address from the stack, set new return address poinitng to our post-function handler and jump back to the original function. After its execution, it calls ret instruction. The last takes the address from the stack and there is a saved beforehand value for our POST_HANDLER. Then, we get to it and have the stack with original parameters and addresses of output parameters.
static
void
__stdcall
NtQuerySystemInfo_HookHandler_PostHandlerImpl(unsigned long * pRetValue,
struct NtQuerySystemInfo_HookHandler_Data * pData,
unsigned long dwOldEax)
{
*pRetValue = pData->dwRealIP;
if ( (pData->SystemInformationClass != SystemProcessesAndThreadsInformation) || (dwOldEax != 0) )
{
FreeMemory(&g_kernelNonPagedAllocator, pData);
return;
}
HideAlgorithm::NtQuerySysInfoParams params = {pData->SystemInformationClass,pData->SystemInformation,
pData->SystemInformationLength,pData->ReturnLength};
HideAlgorithm::HideProcess(params,gProcessChecker);
FreeMemory(&g_kernelNonPagedAllocator, pData);
}As we can see, the restoring of return address and the cleanup of memory allocated by FORE_HANDLER are the tasks of this function. Here, all logic on cutting the required processes from the processes list is performed. I would like to draw your attention to the fact that the cutting is performed by the same algorithm as in the original article of processes hiding.
Execution of the function ends on it.
Splicing Method
In this part of the article, we will study the method of splicing of the original function.
First, we need to allocate memory and write the code to it, which will be called by our handlers. It is performed as follows:
int __stdcall InitializeHookEx(MemoryRWManager * pRwManager, unsigned char * pHook, unsigned char * pHandler)
{
int status = 0;
char buffer[CALL_SIZE];
// Write CALL instruction into buffer
buffer[0] = 0xE8; // 1 byte for CALL opcode
*(size_t*)(buffer + 1) = (unsigned char *)pHandler - (pHook + CALL_SIZE); // 4 bytes for relative address
// Copy CALL instruction from buffer to hook memory
status = WriteMemoryWithWriter(pRwManager->pWriter, (char*)pHook, buffer, CALL_SIZE, 0);
if (status)
return STATUS_UNSUCCESSFUL;
return STATUS_SUCCESS;
}Of course, having allocated memory beforehand, we write the call instruction to it, which will pass the control to FORE_HANDLER. After that, we need to write the code to the original function. Here are some nuances that we should know.
Let’s look at the InstallHook function.
It is designed for patching of different functions and works with them in the same way. If you look at the CommonPatcher.h file, you will see the description of many forms of functions’ prologues in it. And if we identify one of these prologues, it is passed to InstallHook for the further patching. After we discover which instruction there can be and, correspondingly, will be patched, we move its code to a stub, created beforehand. We perform this to make it execute after exiting FORE_HANDLER. It’s clear that without this, everything will work too badly and that it is a required step. Instead of this instruction, we write the jmp command to our stub that leads to FORE_HANDLER.
To make it clear, let’s look at the disassembled code of the NtQuerySystemInformation function before and after splicing and also at the order of instructions execution.
Code before splicing looks like the following:
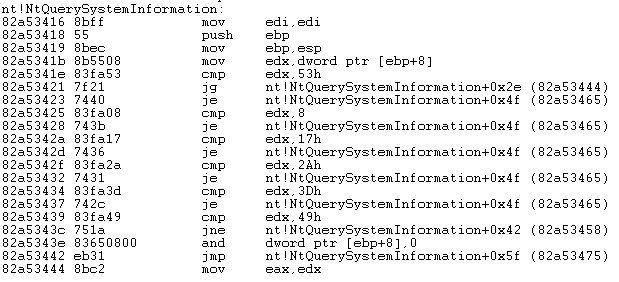
After splicing, we have the following result:
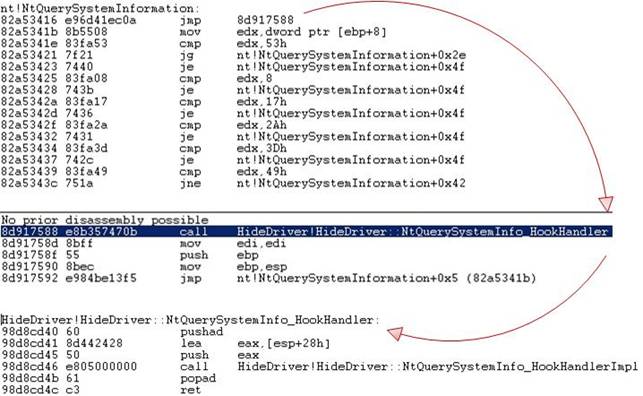
At the beginning of the function, we get jump to our stub instead of the prologue.
In the stub, we pass the execution to NtQuerySystemInfo_HookHandler that sets (substitutes) the return address from NtQuerySystemInformation to our POST_HANDLER and allocates memory for parameters. After that, the prologue of the original function is executed:
movedi,edi
pushebp
mov ebp,espand only after that we return to the original function.
After the execution, our return address is located in the stack and we get to our POST_HANDLER.
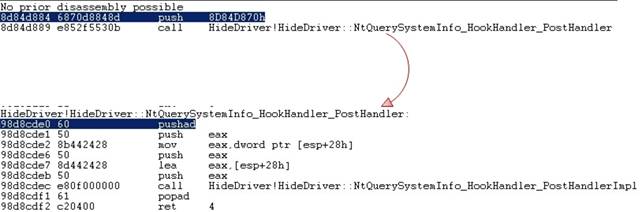
In the handler itself, we write to stack the address of the pointer to our context and call PostHandlerImpl.
Results
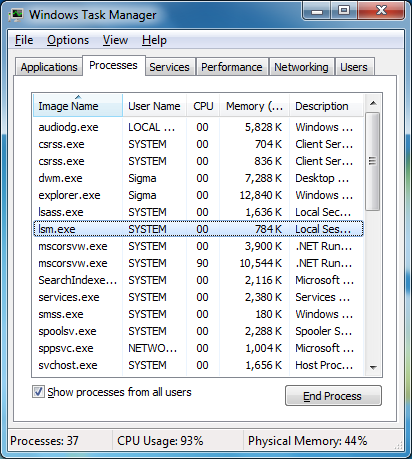
Results of execution look like the following:
Look at the processes list before adding the rule:
Now, add the rule:
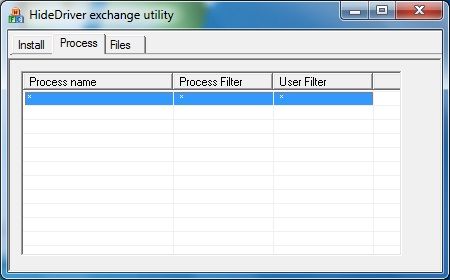
The “*” rule hides all processes.
Look at the result:
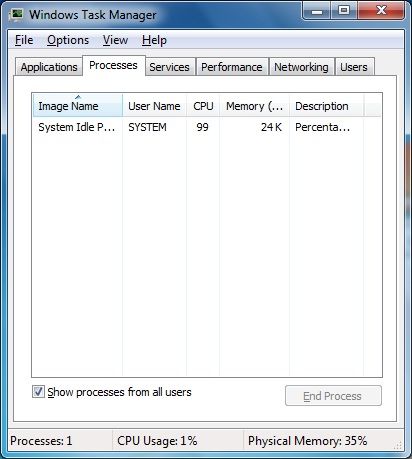
Conclusion
As you noticed, it is a very complicated and nontrivial approach but it proves all the complexity because its discovery is a more difficult task than the SST hook. This technique is also dangerous because you won’t avoid BSOD in case of any small mistake. That is why you should make sure that you fully understand the material before you use this method in real projects.
Additional Information
Project build, structure, separate parts and utilities stayed unchanged in comparison with the original Driver to Hide Processes and Files and Simple SST Unhooker articles.
Bibliography List
- Mark Russinovich, David Solomon. Microsoft Windows Internals ((Fourth Edition) ed.)
- Greg Hoglund, Jamie Butler. Rootkits: Subverting the Windows Kernel
- Gary Nebbett. Windows NT/2000 Native API Reference
- Sven B. Schreiber. Undocumented Windows 2000 Secrets – A Programmer’s Cookbook


