 Skip to main content
Skip to main content

In one of our previous posts, we talked about the basic principles of man-in-the-middle attacks and ways of intercepting SSL and HTTPS traffic with SSLsplit. Now, we’ve decided to focus on how to set up a transparent SSL proxy using the idea behind MITM attacks.
This article describes a two-phase experiment we conducted to see whether it’s possible to create a transparent SSL proxy on a regular PC that can handle more than a million concurrent connections. And leaping ahead, we can say that we almost achieved this goal.
Idea
Figure 1. An SSL/TLS connection
By design, our Linux transparent proxy was part of a complex security solution. We had a black box that could inspect unencrypted traffic and apply some rules based on it. So the main purpose of our proxy was to decrypt SSL/TLS traffic that could be further checked by that black box. And since decrypting the traffic and sending it back to the black box required using private keys, our proxy needed to be able to perform actions similar to those taken during MITM attacks.
We divided our project into two phases:
- Implementing a low-performance proxy with all the necessary functions based on the Linux kernel stack and SSLSplit. SSLSplit is a tool designed for performing a transparent and scalable SSL/TLS interception. It’s a complete solution for testing MITM attacks that already supports not only SSL/TLS but even STARTTLS.
- Making it work on the userspace kernel stack which, in theory, should significantly improve the performance of the proxy.
We chose OpenFastPath (OFP) as our TCP userspace network stack because it’s distributed under the BSD license and supposedly is able to do exactly what we needed to do within this experiment.
Now let’s get into the details of the first phase.
Phase 1. SSLSplit
Figure 2. SSLSplit
We started with a PoC based on SSLSplit.
Basically, SSLSplit performs transparent SSL interception, creates two separate sessions, and forwards data between them. So you can use SSLsplit to transparently sniff SSL connections.
To be able to accept connections from anyone, we created a listening socket using the IP_TRANSPARENT option. Then we had to ensure that all required traffic was redirected to the listening socket we had created, which we did with the help of the iptables tool.
Using libevent, SSLSplit creates an event handler. After accepting connections on the listening socket, the proxy connects to the original destination server and then just forwards data between them. In order to handle these sessions, the proxy uses libevent with its own socket event handlers.
After we set up a simple proxy on a separate machine with two network interface controllers (NICs), we bridged these NICs. We used the ebtables tool for redirecting the required packets from the bridge to our system, and everything worked as expected.
Next, we needed to add session upgrade/downgrade so that our proxy would try to establish its own connections using SSL when we accepted raw TCP sessions, or vice versa. This addition may be helpful for implementing other features. This step also was successful.
Now we needed to create a loop session by sending decrypted traffic to ourselves. This session consists of four major steps:
- The proxy accepts SSL connections
- The proxy creates TCP connections with the new destination source (in our case, ourselves)
- The new destination source establishes a raw connection with the proxy
- The proxy creates SSL connections with the original destination
Since we already had an implementation that could encrypt and decrypt traffic, we decided to use two SSLSplit instances, one for upgrading traffic and the second for downgrading traffic. But when we tried to run them together, all the downgraded traffic was dropped somewhere.
As it turned out later, the problem was in the specific kernel setup: by default, all packets sent by a machine will be dropped if they’re returned. In an ordinary case, this is a routing problem but not part of the logic (who needs to send packets to themselves through the network?). However, you can disable this behavior.
Unfortunately, we made this discovery when we were modifying kernel flags for a debug build after the experiment was already over.
Additional issues
We ran into one more issue: our proxy had to be both connection-oriented (for SSL) and transparent. We could achieve this level of performance with the help of the iptables tool. The problem was that this approach required creating more than five rules for each connection, which was not acceptable if we were to handle a large number of users.
One possible alternative was to use an iptables extension. However, it had to be way faster than the current rule applier and also able to be synchronized with SSLSplit.
We could also use OpenFastPath (OFP), a userspace TCP stack that supports C++ with STL. This stack has two main advantages:
- It’s easy to debug, at least compared to kernel debug
- It gives us full control over a packet from the moment it arrives at the NIC
In addition, moving to the userspace TCP stack was part of the second phase of our project anyway. So we decided to skip the step with SSLSplit and start the next phase of the experiment with OFP.
Phase 2. OFP

The second phase of our experiment was focused on using OpenFastPath (OFP).
OFP runs on OpenDataPlane (ODP), a library that interacts directly with NICs. For the x86 architecture, ODP uses a Data Plane Development Kit (DPDK) as the backend. Using the ODP/DPDK userspace program, you can get an Ethernet frame directly from a NIC and decide what to do with it, and OFP can manage all these packets.
OFP provides APIs that are similar to the Linux network APIs and a wrapper that implements most Linux network APIs with its own functions. So in theory, you can use the compiled binaries with OFP by simply adding a wrapper to the LD_PRELOAD variable.
At first, we tried to use the OFP wrapper with SSLSplit, but it didn’t give us the results we wanted. So instead, we decided to write our own implementation. We already had a simple TCP forwarder which was our PoC and which became the basis of our proxy.
In the beginning, the proxy could only accept direct connections to its IP address and some predefined port and establish its own connections to our local server. So our first step was to make the proxy able to accept all connections to all IP addresses and all ports.
We started by solving the problem with IP addresses. While in the original Linux stack the IP_TRANSPARENT flag is responsible for this task, OFP doesn’t have any similar flags. But since this flag only disables matching the destination IP with the local IPs, we found the part of OFP that’s responsible for this task and modified it to make it possible to process all packets.
Handling connections
Our next step was to make the proxy able to accept any connections. As the proxy controlled packets from the moment they arrived to the NIC, we decided that for the moment, we could open a listening socket on a port from the received SYN packet.
But there was an alternative – to redirect all connections to a single server socket. We rejected this idea, however, because the listening socket buffer was limited and lifting these limitations, as well as redirecting the connections, would have required a lot of changes in OFP, which we tried to avoid.
Our next problem was finding a way to save information about the original connection. At this stage, we used a global table with connection contexts. The proxy received all the information with SYN packets and saved it to the table. When the proxy needed to establish its own connections to the original destination server, it could find the required information in the table using the client source IP and port.
At this point, we found another issue: the current implementation used blocking operations while OFP, as it turned out, has only non-blocking connect operations. This means that when connect returns with a success code, the socket actually isn’t connected yet. So before processing data from the client, the proxy should somehow ensure that the socket is indeed connected successfully.
To solve this problem, we added a loop that checked the socket state for 70 seconds after connect was called. Data forwarding started as soon as the socket state switched to “connected.” If after 70 seconds the socket remained disconnected or there was an error, the proxy closed the client connection.
Next, we decided to implement transparency. At the moment, our proxy was using its IP addresses for establishing its own connections. For replacing IP addresses at the output, we used the OFP IP output hook. Using this hook, the proxy tried to find data about the connection, replace the source IP and MAC addresses, and recalculate the checksum. But as the packet in the hook already contained the destination IP and port from the original connection, we could get all the information we needed directly from our global table with connection contexts and replace it with our proxy’s data.
Since it’s hard to find a route without the IP address, we also added our own hook to the route-finding code. Instead of searching the route, our hook simply returned the output interface based on data from the global context table.
Epoll challenges
When it was time to make our epoll handling non-blocking, we faced one of the biggest challenges: as it turned out, epoll in OFP is more of a workaround than an actual tool. First of all, there’s only one event: OFP_EPOLLIN. But for successful connection handling, we needed at least two more events: EPOLLOUT and EPOLLERR. So we added them.
When adding these events, we discovered that, in fact, there were no events at all. Every time epoll_wait was called, it simply checked the state of each socket one by one. If the socket state matched some parameters, the EPOLLIN event was returned.
One more important thing about this epoll implementation is that the timeout was implemented as a simple sleep mode. So if there weren’t any events on the sockets, epoll just slept. The good news was that adding two new events was quite easy. The bad news was that the performance of this epoll implementation was terrible.
We discovered another issue – socket leaking – when we tested our solution. In general, the main problem was in our handling. The socket could be closed only if the recv() function returned 0 or an error, but our epoll implementation returned EPOLLIN only if some information was received. So if we received a single ACK, the socket would remain open. We solved this problem by adding one more epoll event – RDHUP. After doing so, our TCP proxy performance was more or less stable.
Next, we moved on to solving the problem of saving information about connections.
Saving connection contexts
Finding the right place for cleaning up connection contexts from the global table was quite a challenge. We used data from the global table for sending packets, and that data could still be needed after closing a socket. For instance, the proxy would need to retransmit FIN if FIN wasn’t ACKed. And this meant that we couldn’t delete this information right after a socket was closed.
In order to find a solution for this problem, we performed additional research. Every TCP socket has its own TCP control block – a structure that saves important data such as socket state, sequence numbers, timers, and so on. This structure represents a TCP session in the network stack and is stored for as long as the network stack needs any information about the TCP session. This structure is deleted only after the session is closed and the processing of all timeouts and errors has finished. As a bonus, the TCP stack has access to this structure in almost every function, and if the proxy has a socket, it also can access this structure.
So we added a structure containing information about the original connection to OFP and then added a pointer to that structure to the TCP control block. At this point, every time the proxy accepted a connection and successfully created a new socket, it added the required information to the TCP control block. And when the proxy created a new socket for an outgoing connection, it copied the data from the accepted socket so that the lower layers knew the destination.
Thus, the proxy could get the connection context anywhere and this information would be deleted only when definitely no longer needed. Plus, there was no need for the proxy to perform lookups in transparency hooks as it could use the data directly from the TCP control block.
The expanded frames problem
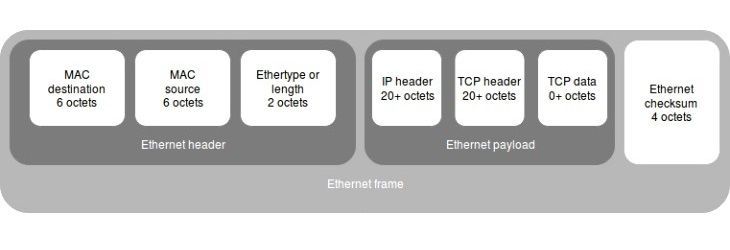
Figure 3. Ethernet frame illustration
As we went on with our experiment, the majority of the applications worked fine, except for Sampa and iperf. These two applications refused to work on Windows, while with the Linux client we had no problems. We found the reason after some additional debugging: the processing of the expanded Ethernet frames.
The thing is that Linux uses timestamps by default and Windows doesn’t. This means that the minimum size of the L2 frame (of the TCP packet OFC) for Windows equals 58 octets (14 (Ethernet header) + 20 (IP header) + 20 (TCP header) + 4 (frame checksum)). But the minimum frame size for sending packets through Ethernet is 64 octets, meaning that this frame will be expanded.
Since Linux uses timestamps by default, the frames are always larger than 64 octets. That’s why frame processing in OFP is implemented in a pretty straightforward manner – after the processing of a header has finished, the header is dropped without any length checks, giving us only the packet payload in the end.
But in the case of Windows packets where the payload is smaller than 6 bytes, we get extra trash data. For example, when the iperf tool sends 1 byte of data, the receive function in the proxy returns 6 bytes of data. This data is then successfully forwarded further, causing errors on the iperf server side. When we added length checking before dropping the TCP header, the problem was solved.
SSL and payload corruption
Our next step was adding SSL handling. We took the basic mechanism for the interaction between OFP and SSL from the OFP Nginx implementation, which is quite similar to the wrapper implementation. Since we needed to save a lot of SSL parameters and pass them between the connections, we also had to change the connection handling.
At the testing stage, we discovered random session dropping. After some research, we learned that when overloaded, the OFP TCP stack can corrupt incoming data. The main problem was in the handling of incoming packets. We found the exact same bug in the OFP GitHub repository, and it was closed as fixed.
The problem was caused by the function that adds information from the packet to the socket – it drops packets if no space is available on the socket. At the same time, the return value of this function isn’t checked and the stack keeps acting like everything is okay even if the packet has been dropped. As a result, the plain TCP session receives less data and the checksum of that data doesn’t match the original, but the session is still processed successfully. However, in the case of SSL, the proxy will get a decryption error and the session will be closed.
OFP developers fixed this issue by simply adding a check for free socket space. While not being a completely correct solution, it works well in most cases. However, a proxy may receive a large number of out-of-order packets when being put under high input. For instance, if one packet is lost but the following packets are received successfully, these packets will be added to a reassembling queue that serves as a temporary buffer. When the missing packet is received, the proxy will check this queue for the packets that could be added right after the newly received one.
This feature increases performance since the other side doesn’t have to duplicate all of the recently sent packets and only needs to retransmit missed data. However, the current fix didn’t work well because it allows adding large amounts of packets to the reassembling queue even if the socket has enough space for only one packet. We fixed this issue.
Finally, we could start performance testing.
Performance and 1 million connections
After SSL stabilization, we moved to the performance testing stage. As it turned out, our proxy could handle only 14,000 to 15,000 simultaneous connections. This poor performance was caused by our transparency implementation. Since our proxy didn’t have an IP address and used the client IPs instead, we didn’t use our IP address to bind sockets to the interfaces. Thus, the only thing that allowed our proxy to distinguish one connection from another was the source port. For establishing all the needed connections, our proxy required four sockets (one client socket, two sockets for the black box, and one more for the server), and it had only 64,000 sockets not bound to any interface. Also, we still hadn’t gained full 5-tuple transparency.
In order to solve both of these problems, we changed all lookups based on the packet’s 5-tuple and added a sixth parameter – the address of the input interface. This addition allowed us to accomplish two tasks:
- Bind the sockets to the device automatically without using the device IP address – This allowed our proxy to handle the packets with the same 5-tuple and still be able to distinguish the original client connections from its own connections processed through the black box, as they used different devices.
- Lift the limitation of the number of ports that could be used by the proxy – Since we didn’t use any of the proxy’s own information for handling TCP sessions, the number of ports we could use became virtually unlimited.
We managed to build a fully transparent SSL proxy that can perform MITM attacks, can handle an unlimited amount of connections, and supports STARTTLS. The only problem was the OFP epoll implementation that actually worked as a simple array.
We tried to improve the OFP epoll implementation, but in order to gain a high level of performance and make a real event-based handling mechanism, we would have to fully rewrite it. Also, with the increased complexity of the SSL logic, we got some new issues. And unfortunately, we didn’t have enough time to make any of these improvements.
Conclusion
Even though we didn’t accomplish our main goal, this experiment was rather useful. We saw that ODP/DPDK works really fast: we tested our proxy in the L2 forwarder mode on a 4th generation Intel i5 CPU and were able to handle four 1GbE NICs at full speed in full duplex on a single core. Probably, the results could have been even higher, but we didn’t have better NICs available. Also, the handling thread worked in polling mode, so the CPU was under 100% load anyway and we weren’t able to check the real load.
The idea of using OFP also proved to be great. The userspace TCP stack has great scalability and allows developers to optimize packet processing for their needs. For example, you can increase throughput with a low level of latency increasing and vice versa by using burst mode (when packets are processed in groups).
As for development, it’s way easier and safer to work in the userspace (especially for debugging). OFP can be used for C++ projects because it allows you to easily implement efficient traffic filtering mechanisms meant to check hundreds of rules for every packet. Also, you can use the OFP wrapper for launching compiled binaries.
Still, the current implementation of OFP has a lot of issues: connection handling needs to be improved significantly and there are a lot of bugs related to packet handling that OFP has inherited from FreeBSD.
Userspace TCP stacks are powerful solutions for high-performance network applications. But unfortunately, OFP isn’t a contender, at least not yet.


