 Skip to main content
Skip to main content

This article is for those who write or are going to write functional tests for any programs. The goal of this article is to give the flavor of the main techniques of test design and also to answer the question: What method is better to choose for testing your project?
It’s simple to complicate, it’s complicated to simplify.
Meyer’s law
Contents:
My first tests or What are the techniques of test design for?
When I began testing I didn’t know any of the techniques of test design even their names. And the tester who was my tutor for the first days of my tester life knew about that. But she just gave me a project and said: “Write tests”. The most interesting is that the result was rather good. Actually each user can write good tests for the simple small program even without knowing any technique of test design. So I remembered my first “methodology” of test writing, which was formulated by my testing sensei as “Use the common sense”.
Time was passing; the project was growing and me too. And one day I found that just the common sense was not enough. Tips that worked for the simple project didn’t suit the complicated one. It became hard to keep in mind all tests: created and just incipient ones. It became obvious that sometimes there were more tests than it was really necessary. And that was the moment when I needed the techniques of test design.
After I had read about these methodologies I was surprised because it discovered that I had used them more or less in my practice for a long time already. I found that when a tester used them consciously he got almost complete algorithm to compose check lists. You don’t have to keep everything in your mind as soon as the techniques of test design are the tool to manage complexity.
It’s especially important for the big projects.
How to make the infinite work in the finite terms?
Testing theory tells that it’s impossible to test functionality completely. Because if we speak about the black box testing to test the functionality completely means:
– check all ways of the program behavior
– check all combinations of the input data
– check all sequences of the input data
– check all possible actions over the user interface up to the stand-alone pixel.
It’s absolutely obvious that it’s impossible to perform in the reasonable time.
Any check list, any test case group is a cut version of the full test set (which is never used) containing some set of test that can be performed in the reasonable time. Of course we have a risk here that some bugs won’t be found during testing.
The goal of the techniques of test design is to compose such set of tests that can be performed in reasonable time and minimize the number and seriousness of the unfound bugs.
Let’s consider some techniques.
Equivalence Partitioning
Main idea: make partitioning of the whole input data set in the equivalence classes. Each class contains so similar data that it’s senseless to perform tests on two different elements of it. Thus if a test on one element discovers an error then it’s natural to suppose that this test on any other element of this equivalence class will also give an error. So it’s enough to perform the test on one element from each class.
There should be at least two equivalence classes: correct data for positive tests and incorrect data for negative tests. Usually there are more than two classes.
Example 1: Let’s suppose that we test a field «month», that gets integer values from user and shows the name of the month by its number.
The simplest variant of equivalence partitioning:
- month < 1
- month [1; 12]
- month > 12
It’s obvious that the second class contains correct values for month number and we can use any of them for the positive test: for example, 12. The first and third classes contain incorrect values for this field which shouldn’t be accepted by the program.
There can be a reasonable question: why not to merge the 1st and 3rd classes into one equivalence class? Is the checking of values from both classes redundant? The answer is the following: if we don’t know how the input is implemented (and in black box testing we don’t) then there is a risk that a developer missed some moments – and we can miss them too. And anyway we should not make our tests dependent on the implementation. They should depend only on the specification.
Let’s return to the example. We have 3 classes but if we look attentively at the first one we notice that the class includes such special element as 0. If one of the classes contains some special element we can put it in the separated equivalence class:
- month < 0
- month = 0
- month [1; 12]
- month > 12
We choose one element from each class, to say, we can perform the test with -5; 0; 8; 15. If we input the value 8 we should get the answer “August”. In all other cases program should show the error message.
The equivalence partitioning for the months can be also not so simple. It depends much on the task context. For example some tourist program can behave in different ways for the summer and winter months. And accounting program behavior will differ for the months when the reports should be prepared and so on.
What entities can be divided on the equivalence classes?
- numbers
- chars
- dates
- string length
- number of smth. (records in DB, lines, list elements, nesting levels etc.)
- file size
- OS versions.
Example 2: The user registration form has the text field Login. Correct user name has from 3 to 20 chars. It can consist of the Latin letters, numbers and underscores. Let’s divide input data set on the equivalence classes. It’s more difficult than in the previous example as the common sense tells that the combinations of parameters will give different equivalence classes, but first we’ll try to do it without combinations.
Equivalence classes for the symbols:
- Latin lower case letters
- Latin upper case letters
- Numbers
- Underscores
- No Latin lower case letters
- No Latin upper case letters
- Space
- All other no letter-number symbols such as «№;!»*():
Equivalence classes for the string length:
- Zero length (empty field)
- 1 or 2 symbols
- From 3 to 20 symbols
- More than 20 symbols but less than the upper limit permissible for this field
- More than the upper limit permissible for this field.
Logic tells that to use all these classes we should consider all combinations between them. There will be a lot of tests and our check list will be overweighed. There are methodologies to cut the number of test sets and achieve noticeable saving of testing time with insignificant increase of the risk. We’ll consider them later.
Now we can describe the algorithm of equivalence partitioning:
- Enumerate all input data
- For each input parameter perform equivalence partitioning
- Build class combinations
- Take one element from each class combination and perform test on it.
The last step in this algorithm seems to be a little bit unclear. The class can include a lot of values and it’s not clear which to choose. The next method will help us.
Boundary Value Analysis
Boundary Value Analysis method is the improvement of the equivalence partitioning. The key point is to focus testing on the boundary and extreme values of the equivalence classes. The problems most frequently appear on the transit elements, minimums, maximums and other specific elements.
Algorithm in this method is almost the same.
- Enumerate all input data
- Perform equivalence partitioning for each input parameter
- Build class combinations
- Take one element from each class combination and perform test on it.
But on the last step we choose not any value from the class but the boundary, near-boundary or special values.
Let’s return to the Example 1 ( “month” field). We built the equivalence partitioning:
- month < 0
- month = 0
- month [1; 12]
- month > 12
and chose the values -5; 0; 8; 15 for the tests. If we apply the Boundary Value Analysis we should perform test on the values -1; 0; 1; 2; 11; 12; 13 and, maybe, upper and lower bounds for the fields.
The boundary values can be not only numbers or intervals but also any extreme cases for different entities, for example:
– the first or the last (current) database transaction
– the first file saving
– the beginning or the end of the page
– the first or the last element of the list
– empty or overloaded tables/files
Etc.
Cause Effect
Cause-Effect Graphing initially was the technique of hardware testing (electronic circuits) and later was adapted to software testing. This technique refers to the black box testing.
The method uses the visualization of logical connections in the system. It allows to choose the input data combinations that are really reasonable to be transformed into tests.
Method consists of 4 steps:
- Determine the causes and effects described in specification.
Cause is the individual value of system input or the class of the input data i.e. any term of the specification that influence the result.
Effect is the output value, the result of the system transformation.
Each cause/effect is written and the identifier is assigned to it. An effect can be also the cause of the other effect.
- Next step is to build the Cause-effect graph that is the oriented graph with causes and effects as nodes connected by Boolean operators.
There are some standard designations:
If A unconditionally causes C then the simple line is drawn.
If A or B causes C then V sign is drawn.
If A and B causes C then reverse V is drawn.
If A doesn’t cause C then ~ sign is used.
- Transform the graph into the Decision table.
- Transform the Decision table into the test cases.
Let’s consider an example.
Example 3: Let’s suppose that requirements contain the condition: «If A OR B then С». The next statements illustrate this condition:
• If A is true and B is true, then C is true.
• If A is true and B is false, then C is true.
• If A is false and B is true, then C is true.
• If A is false and B is false, then C is false.
Cause-effect graph:
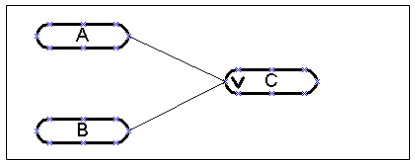
Nodes A and B are causes, node C is effect. Each node can have true or false value. Vectors connect A and B with C.
Cause-effect graph is transformed to the Decision table or Truth table that reflects logical connections between causes and effects. Each column of this table will be then transformed into the test case. Each column represents the only possible combination of the input data and corresponding out value that can be one of three: true, false or masked state. The last value means that this test doesn’t matter – “don’t care test”.
Thus for two input parameters in our example are 22 = 4 full combinations.
Decision table for our example:
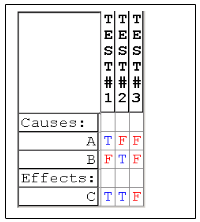
You can notice that there are only 3 test cases in our table as far as they cover 100% of functionality in our example. The fourth combination of input data (А = true, B = true) doesn’t bring anything new and this test case is omitted.
For more details about this method read the Requirements-based testing – Cause-Effect graphing by Gary E. Mogyorodi.
On the one hand this method is rather complicated even for the simplest requirements, on the other hand it is reliable and provides the maximum coverage with the minimum test number. In practice the specialized software is used to apply this method, it automatically transforms requirements into the graph and the graph into the decision table.
Error guessing
This technique can hardly be called the methodology of test design in full meaning. But when applying it to the testing it brings rather good results and even more, each tester unconsciously uses it.
Key point of error guessing is that tester relies on his last experience and performs the tests that he expects to show the error in the first turn. There are no specific tools or algorithms for this technique. Error guessing is akin to the exploratory testing. The effectiveness of this method depends much on the tester experience: if tester A worked on the 30 projects and tester B in 5 only, then most likely tester A knows better where to wait errors from in his 31st project than tester B in his 6th one. Such qualities as imagination, creativity and good knowledge of the soft hardware platform of the application to be tested are important too.
Experienced tester waits errors from a lot of situations. The most suspicious ones:
– empty files and database tables
– overflow
– disconnections
– spaces and non-Latin symbols in the file names and edit fields
– results of the complicated specific checks and calculations
– specific OS settings: for example UAC, font sizes and display resolutions
Etc.
Anyway each new project, each new test gives priceless creative tester experience, knowledge about where bugs can come from.
User Scenario testing
Applying this method tester performs not test cases i.e. all possible cases in the system but user scenarios. User scenarios are some likely stories about what a user can do in the tested system.
Cem Kaner gives 12 perfect advices to write the good user scenario:
- Write life stories for system objects.
For example for some financial credit program you can create a story when a person borrow money and bank worker create an agreement and open the special balance; a story where somebody fail into arrears for his credit and then paid them later or disappeared in the unknown direction. Such stories reflect the situation which can happen in the real life and which the system should react to in the proper way.
- Make the list of the possible users and analyze their interests and goals.
Users of above-mentioned credit system are bank workers who work directly with the clients, bank managers who endorse the credit limits, bank accountants and also inner and exterior auditors. Each of them uses the system for his specific needs, deals with the specific functionality.
- Consider the unwanted users. How can they harm the system?
For example, if to give access to the system for the clients to look up their remaining debts, payment history etc. – its good practice. But if such client gets the access to the system changing or credit history of other clients he can use this miss.
- Make the list of the system events. How does the system process them?
- Make the list of the specific events. How does the system adapt to them?
Specific event is the predictable but unusual situation, for example the closing of the financial year for the bank.
- Make the list of the benefits of this system and create the full scenarios to check them. Don’t base only on the official list of the system advantages.
- Ask users about the problems and fails of the old system.
- Watch the users to see what and how they do.
- Learn the knowledge domain: read about what the system performs.
- Learn complains on the previous similar system or your competitor system.
- Test the system like you really work with it. You need realistic simulation.
For example, if you test a text processor then work with the documents that you really need and use.
- Try to convert the real data from the previous system or competitor system.
Advantage is that the real data already include various cases that happened in practice. It will show how the new system deals with them.
Read more in “An introduction to scenario testing” by Cem Caner. http://www.kaner.com/pdfs/ScenarioIntroVer4.pdf
Passing through the test scenarios has the indisputable advantage: first we test the functionality that the real users will work with. It’s for sure the highest priority for each tester. Besides scenario based testing usually covers several functionalities and gives a possibility to test properly their interaction.
But stand-alone testing of the user scenarios leaves the project unprotected from the user faults, hardware faults and other emergencies and unlikely situations.
So user scenarios are the perfect technique to create the tests of the highest priority, but you cannot make the test plan based only on this method.
Risk based testing
Risk based testing also helps more to prioritize tests than to create them. Tests get their priorities according to the probability of bug appearance and the importance of its effects.
The method supposes:
- Analysis of the most important and critical functionalities.
- Analysis of the fields and actions with the highest bug probability.
- Analysis of the bug effects on the functionality components.
Thus first of all the requirements are analyzed to detect the most important functionalities. Then we start to look for the bottle-necks and vulnerabilities of the system and also analyze the possible effects of the bugs there. After detecting the most unwanted events for the system tester supposes that they happen and start the purposeful search of the bugs of the specified type.
For example, in some application the bottle-neck can be the connection between server and database. In this case the tests for disconnects, band speed limits etc. will get the highest priority.
Using the risk based testing technique we can allocate testing efforts to avoid the most critical bugs in the most critical places.
Methods of cutting down the number of tests
Sometimes the full amount of tests created is too big to perform with the current resources. In this case we should cut down the number of tests, using some assumptions.
For example we have such search form:
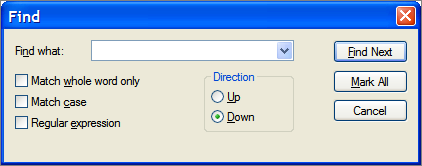
There are 5 variables:
- Find what (FW) – string
- Match whole words only (MW) – Boolean
- Match case (MC) – Boolean
- Regular expression (RE) – Boolean
- Direction (D) – enumeration (Up, Down)
Test values
- FW = {‘lower’; ‘UPPER’; ‘MiXeD’}
- MW, MC, RE = {Yes; No}
- В = {Up; Down}
Result: 3 х 2 х 2 х 2 х 2 = 48 tests
For such cases the prioritization based on the risks or scenarios doesn’t work. We can either perform the whole number of 48 tests (that is good for automated testing and really poor for the manual one), or use one of the 2 cut variants: all pairs (each value with each value) or all values at least once.
Exhaustive search: we build the table for 48 tests, each row contains the combination of the options for the specified test. All tests are considered with the same priority.
| FW | MW | MC | RE | D | |
| 1 | L | Y | Y | Y | Up |
| 2 | U | Y | Y | Y | Up |
| 3 | M | Y | Y | Y | Up |
| 4 | L | Y | Y | Y | Up |
| 5 | L | N | Y | Y | Up |
| … | … | … | … | … | … |
| 47 | M | N | N | N | Up |
| 48 | M | N | N | N | D |
All values at least once. We also build the table. The parameter with the biggest number of input values (for our example it is the string) possesses all its values once, values of other parameters are repeated in random order. There are no more important or less important combinations, they are made randomly.
| FW | MW | MC | RE | D | |
| 1 | L | Y | N | Y | Up |
| 2 | U | N | Y | N | D |
| 3 | M | Y | Y | N | Up |
All pairs. This method is the happy medium for the previous two. It provides rather good coverage with the reasonable number of tests. But this method works well only for independent variables.
| FW | MW | MC | RE | D | |
| 1 | L | Y | N | Y | Up |
| 2 | L | N | Y | N | D |
| 3 | U | Y | Y | N | Up |
| 4 | U | N | N | Y | D |
| 5 | M | N | N | N | Up |
| 6 | M | Y | Y | Y | D |
So what to choose?
It’s not good to limit yourself with just one method. Usually various combinations of the described techniques are used.
Equivalent partitioning, Boundary value analysis, Error guessing and also associated methods of cutting down the number of tests are always used in the projects to make test sets – consciously or subconsciously.
There are no universal recommendations when to use such and such technique of test design, but some of them are adapted for the specific classes of software.
Risk based testing is necessary for testing the products with high requirements for reliability and security.
User scenario testing is good for all applications that are oriented on the home user.
Cause-effect method is used in the special conditions. It’s rather complicated and you need experienced staff and special software to use it.
In common you can use the following combination for the black box testing:
- Detect the highest risk scopes
- Define the user scenarios and their parameters
- Perform equivalence partitioning and write test scenarios
- Cut down the number of test scenarios if necessary.
Conclusion
I want to remind that any technique of test design is the tool of complicity management, the possibility not to get lost in the great amount of variations, probabilities and combinations. Be careful when choosing an application security testing methodology. So if the applying of some technique not simplifies the task but makes it harder, it’s better to refuse of it, maybe it’s just doesn’t suit this task.
It’s also worse to remember the main testing technique: “Use the common sense!”


