 Skip to main content
Skip to main content

Testing of Multi-Language Applications
Theoretical fundamentals of modern encodings, process of interaction of code pages inside the OS, specifics of testing and creation of test data are described in this article.
Contents:
Introduction
When creating first computers and first disk management systems (OS parents), nobody thought of multilingual applications. The main tasks of that period were as follows:
- Strict correspondence between the code and the symbol displaying;
- Minimal usage of disk space;
- Minimum amount of information for transfer.
Emergence of personal computers and portable equipment such as laptops, smartphones, pads as well as the increasing information transfer speed and user need in the instant access to this information, influenced the requirements for program systems. A modern user wants to scan mail, news quickly and in his native language and maybe even in its dialect. The main requirements to the software are as follows:
- universality;
- sufficient speed of processing of symbolic information;
World software and PC manufacturers support these tendencies. But such attempt to satisfy the increasing user needs leads to some mistakes. Incorrect conformance between Windows code pages, old ASCII text or surrogate Unicode pairs created a large field for errors, incorrect correspondence of symbols, “mojibake” from the Internet. As a result, we often see a non-readable text in the software interface or on the Internet pages.
As it is known, to detect errors in proper time, testing is performed. We will examine how to test an application to detect errors with symbols encoding.
History of Development from ASCII to Unicode
Information encoding, national encodings
Encoding, or code table, is a table of correspondence between symbol graphic representation and its number, a binary code combination.
Table 1. Examples of ASCII table code combinations
|
Symbols |
Code value |
|
B |
0100 0010 |
|
S |
0101 0011 |
|
w |
0111 0111 |
|
_ |
0101 1111 |
|
~ |
0111 1110 |
Depending on the number of symbols we want to encode, we select the size of the code combination. First encodings included up to 7 bits. In the 0000 0000 – 0111 1111 range, we can encode 128 symbols (in the hexadecimal system, range is 00 – 7F). It will be sufficient for big and small letters of English alphabet, punctuation symbols, and non-symbolic operations.
ASCII was firstly designed as a 7-bit encoding, it included 128 symbols. The 8th bit could be used as a parity bit. Parity bit is a check bit and it serves for checking the general parity of a binary number. It was widely used for sequential data transfer and served as a marker of distortion in the transferred combination. Thus, we could detect one-bit bugs.
Example:
The source combination 0101010 is to receive the parity bit of the current combination, let’s combine all bits by a logical operation Exclusive OR. As a result, we receive as follows:
0+1+0+1+0+1+0 = 1 (as we can see, «1» corresponds to odd number of units in the combination and «0» corresponds to even one)
Let’s add a parity bit to the source combination:
0101 0101
After the transfer, check of the parity bit is performed. For example, there was a one-bit bug:
0101 0101 -> 1101 0101
The receiver defines it by comparing the source and the expected parity bit:
Source = 1
Expected 1+1+0+1+0+1+0 = 0
Later, more complex mathematical algorithms were used, where the Checksum is received instead of the parity bit.
Together with standard expansion, a necessity of encoding for the specific national symbols appeared. Due to this, the 8-bit representation of ASCII table, where all 256 symbols were filled, appeared. And the high-order codes 1000 0000 – 1111 1111 (hexadecimal range 80 – FF) corresponded to the national alphabet and additional signs.
Special tables were created for each script. In its turn, computer manufacturers added new code tables to support. Many code tables are similar to books by their structure where a certain code page is used for encoding of different languages. The historical name “code page” was firstly assigned to changeable tables of national symbols that correspond to high-order codes of ASCII table. Now, terms “code page” and “encoding” are equal.
KOI-8 encoding (code of information exchange) was developed by Russian developers that included both English and Russian symbols. KOI-8 is fully compatible with ASCII by the first part of code combinations 00 – 7F. The high-order part of combinations and Russian symbols are located not in the alphabetical order but according to English letters consonant with it. That is why when losing the high-order bit, we receive «Русский Текст» turned to «rUSSKIJ tEKST». KOI-8-R (original encoding) became an international standard; also, variants for Ukrainian KOI-8-U, for Kazakh, Armenian, and other languages were added.
For decades of development, a number of EBCDIC, GB2312, SJIS, RADIX-50 encodings and a number of code tables (CodePages) from Windows were created and introduced. Most of these encodings were created by specific requirements of hardware implementation or data transfer environment.
Unicode
Incompatibility of different types of encodings lead to an idea of creation of a general encoding standard that would cover a number of languages, dialects, complex hieroglyphs. Unicode became such a standard.
Unicode is represented in the form of a table where signs of a number of world languages are written. Each alphabet (writing) takes a certain table range.
It was thought to be wasteful to use 32 bits for encoding of all table symbols that is why the first implementation was a 16-bit one. UTF-16 (Unicode Transformation Format) is the first format of the Unicode table representation. Symbols with 0x0000..0xD7FF and 0xE000..0xFFFF codes are represented by one 16-bit word. Symbols with 0x10000—0x10FFFF codes are represented in the form of a sequence of two 16-bit words. For representation of symbols with 0x10000—0x10FFFF codes, a conversion matrix is used. The first word of two is located in the 0xD800–0xDBFF range, the second one — in the 0xDC00—0xDFFF range.
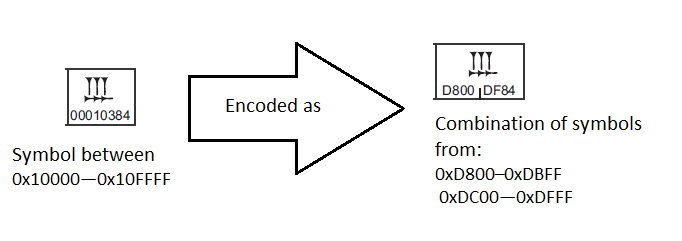
Fig.1. Conversion of a code combination
You can’t meet this range of values among symbols that are transferred with the help of one 16-bit word. That is why encoding decryption is always single-valued. As a result, it is possible to encode 1 112064 symbols.
The area with codes 0000 – 007F contains symbols of ASCII set with corresponding codes. Sign areas with 0400 – 052F, from 2DE0 to 2DFF, from A640 to A69F codes are allocated for Cyrillic symbols. Next, sign areas of different writings, punctuation signs, and technical symbols are located. The part of the codes is reserved for future use.
Encoding of a number of languages in the table lead to allocation of diacritical signs [ْ,֠ ˀ,˘,˞,ˆ,˰,˷] to a separate area. Diacritical signs in typography are the writing elements that modify signs outline. The last are divided into ascenders, descenders, and in-row elements according to place.
Now, let’s analyze possible code representations of the Å symbol. Such symbol is met in several languages. That is why it is duplicated in different areas in the Unicode table and corresponds to 00C5 and 212B codes. Also, representation in the form of combinations – surrogate pairs – is possible. The ˚ diacritical sign is laid over the А symbol from the ASCII area. Its code interpretation is 0041 030А.
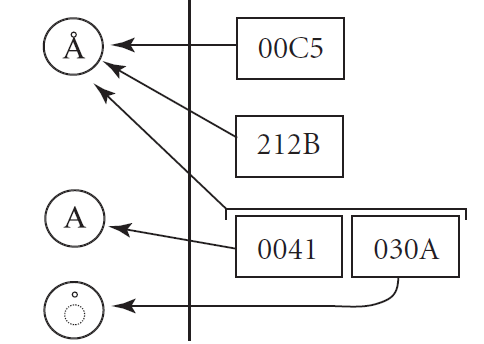
Fig.2. Complex symbol in different alphabets and its interpretation in the form of a surrogate pair
When formatting surrogate pairs, codes from the 0xD800–0xDBFF range only for the first word and 0xDC00—0xDFFF only for the second one are acceptable. The decoder application can clearly define which symbol is the next one – one 2-byte symbol or a pair of 2-byte symbols.
A UTF-8 encoding was developed for the greater compatibility with old 8-bit encodings. It became the encoding standard in Unix and Mac systems. It represents a set of 8-bit combinations. The number of combinations varies depending on the encoded symbol and can be in the range from 1 to 4 (see figure 2 UTF-8).
UTF-8 symbols are got from Unicode as follows:
|
Unicode |
UTF-8 |
Represented Symbols |
|
0x00000000 — 0x0000007F |
0xxxxxxx |
ASCII, including English alphabet, simple punctuation signs and Arabic numerals |
|
0x00000080 — 0x000007FF |
110xxxxx 10xxxxxx |
Cyrillic alphabet, expanded Latin, Arabic, Armenian, Greek, Jewish, and Coptic alphabets; Syrian, Thaana, N’Ko; IPA; some punctuation signs |
|
0x00000800 — 0x0000FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
All other modern writing forms, including Georgian alphabet, Indian, Chinese, Korean, and Japanese scripts; complex punctuation signs; mathematical and other special symbols |
|
0x00010000 — 0x001FFFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
Music symbols, rare Chinese hieroglyphs, dead writing forms |
As we can see from the table, the decoder application can clearly define the number of bytes in the succession by the first bits: 110xxxxx – 2-byte, 11110xxx – 4-byte, etc.
UTF-32 is developed the last according to chronology. In fact, it is a complemented UTF-16 encoding where only the interval from 0х000000 to 0x10FFFF is used. Other bits are filled with zeros. The advantage of this encoding is that the symbol has a constant length and we can get direct access to an i text element. In the previous Unicode versions, it was possible only to come logically to an i element. Disadvantage is that such encoding takes much more space. For example, for the text that consists of English symbols (and this is the majority), encoded information will take twice more space that UTF-16 and four times more space than UTF-8.
Besides, there are encoding modifications where the order of bytes sequence in pairs is important. One symbol of the UTF-16 and UTF-32 encoding is represented by the sequence of bytes. Which of them comes first, the high-order or low-order byte, it depends on the encoding modification (see figure 2). The system that is compatible with x86 processors is called little endian (LE) and the one that is compatible with m68k and SPARC processors— big endian (BE). To define the order of bytes, a byte order mark is used. The FEFF code is written at the beginning of the text. When reading, if FFFE was read instead of FEFF, it means that the order of bytes is reverse because there is no symbol with the code and FFFE in Unicode.
In API Win32, which is widespread in modern versions of Microsoft Windows OS, there are two ways of text representation: in the form of traditional 8-bit code pages and in the form of UTF-16LE.
File names are written in UTF-16LE in NTFS file system and in FAT file system with the support of long names.
When testing applications that work with the decoding of data, it is necessary to check it on data with different order of sequence.
On figure 2, you can see correspondence of codes of different Unicode implementations:
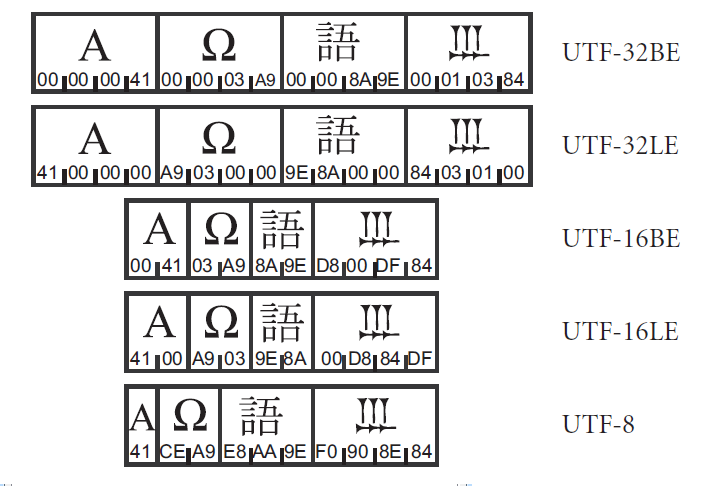
Fig.3. Symbols and their code representation in Unicode
As we can see from the example, symbols of English alphabet, the same 127 ASCII symbols are encoded in the same way; zeroes are added only for 16- and 32-bit encodings.
Data Encoding in Local OS and WEB
Encodings in Windows
As it is known, a program, started in OS, does not display anything and does not carry symbols for displaying. This is the system task. It means that OS must know in which language to display messages, enter and store data. The program sends the symbol code that must be displayed. OS finds the symbol, corresponding to the code, in the table and displays it. This will be the area of the software work that we should test.
Processing of symbols in Windows NT and higher comes in the UTF-16 format. It means that applications developed with the support of this format will not have problems in GUI representation in all available languages.
Regional binding does not influence the displaying of symbols in applications. On the regional parameters tab, you can set the formats of date displaying, currency and other specifics, but not the encoding format.
An option of usage of default language for non-Unicode programs is interesting:
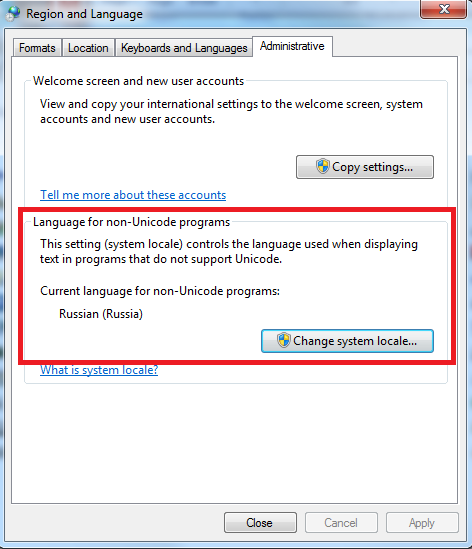
Fig.4. Region and Language settings (Windows 7)
By selecting the Russian language, we set the CP1251 code page by default.
Language Settings in Windows Registry
In windows registry, there is a hive where settings of current code pages, language packs are stored:
HKLMSYSTEMCurrentControlSetControlNlsCodePage
In registry keys, correspondences between the encoding, requested from the system, and table of symbols are stored. In such way, problems with incorrect displaying of Cyrillic are solved by substituting the value in 1252 to с_1251.nls – file with the 1251 code page. CP1251 and CP1252 are used for displaying of symbols in applications in the Russian version of Windows OS. The command line and DOS applications started in Windows with Russian localization will use the CP866 code page. If the value is changed to СP865 in the registry, we will receive «????» instead of Russian symbols.
Encoding in WEB
One of the reasons of encoding development is the development of Internet. A letter written on a PC in an Indian ASCII variant will not be recognized correctly in the Russian variant of ASCII. Internet services were the first to require a universal encoding. Part of information in the UTF-8 encoding is constantly increasing and comprises near 50%. But the significant part of information is stored in national encodings. We will receive unreadable pages because of the disagreement of the last. Now, all modern browsers support UTF-8.
Web developers usually define the code page with the help of the META tag as follows:
<META Name=”Content-Type” Value=”text/html;charset=utf-8″>
If the encoding is not defined and the test is not recognized as Unicode, then the browser selects the code page according to the system settings.
Encoding in Unix-like systems
KOI-8-R is a standard encoding in Unix systems. To view texts in other encodings, you need to use programs – convertors such as Russian Anywhere for UNIX.
In Mac OS systems, there are their own encodings that are displayed as CP10000, CP10001 in Windows and are identical to CP1250, CP1251.
Also, in the process of Unicode development, all Unix-like systems including Mac OS added the support of UTF-8 that is maximum compatible with the old one-byte encodings.
Most Common Problems in Testing
In this part of the article, on the basis of examined information about symbols representation, we will try to underline what you should pay attention to while testing your application.
One of the mistakes in understanding of encodings testing in applications is that the testing comprises in change of localization and default language. In such way, only the OS behavior and the degree of how unattractive the incorrect symbols will be displayed by your application are tested. Of course, you need to make sure that the program displays symbols in a guaranteed encoding correctly and also monitor the behavior when a not supported encoding is installed.
For example, let’s take Russian versions of QIP and WinRar:
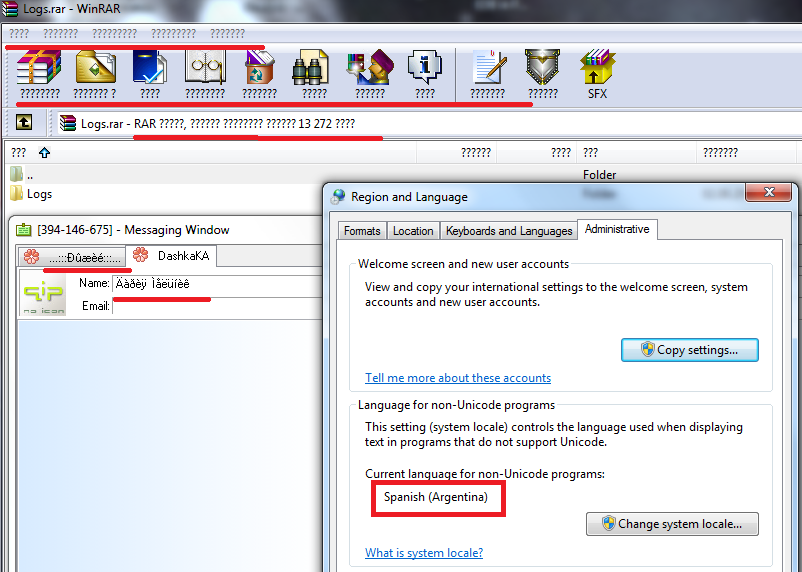
Fig.5. Incorrect localization
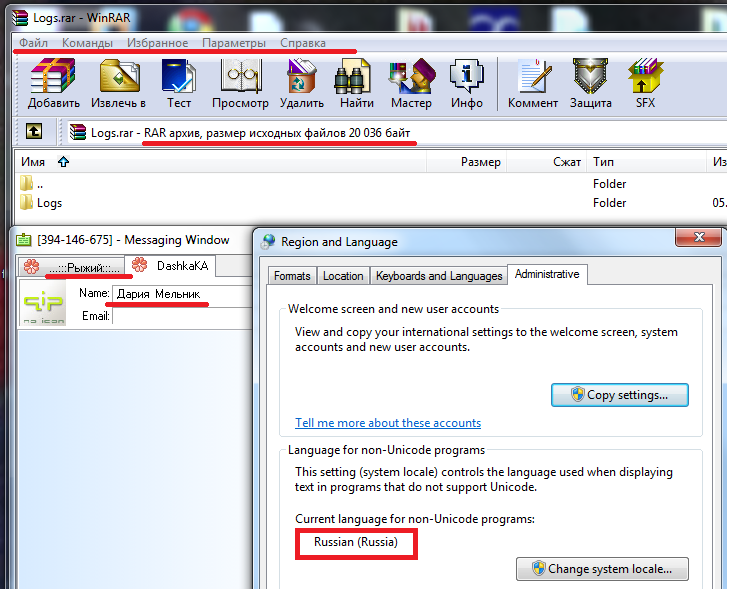
Fig.6. Correct localization
Errors in processing the paths with Unicode symbols are a very frequent problem. For example, if the program is written in VisualStudio with the support of UTF-16, all GUI elements will be displayed correctly and all functions will work fine. But if the installer is written with the help of command scripts, a problem can occur: a command of transfer of path from the script to the main code transforms it to ASCII implicitly. The conclusion is as follows: applications should be checked for the support of paths with Unicode symbols in such places:
- Installation, unpacking;
- Opening, saving of files.
For example, WinRar converts the folder name in the Unicode format not correctly. As a result, further actions with the folder lead to the name loss:
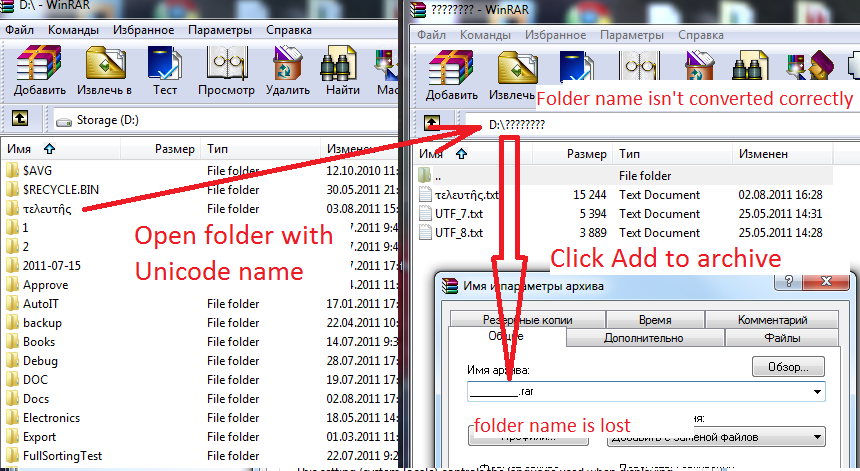
Fig.7. Incorrect decoding of the file path from the Unicode format
Fields for entering customer data (EditBox, ListBox, MemoBox) should be tested for the support of Unicode, especially when data is transformed and saved in memory in the form of structures or databases. In these cases, transformations of types and encodings are possible.
To enter Unicode symbols in Windows, you can use key combination ALT +XXX, where ХХХ – symbol number in the Unicode table.
In Unix, symbols can be entered by the combination Ctrl+Shift+ FFFF, where FFFF – hexadecimal symbol code.
In Mac OS, you can use combination Option+ FFFF, where FFFF – hexadecimal symbol code.
A lot of test pages are created in the Internet for browsers with the help of which you can check data decoding. Examples are as follows:
http://www.columbia.edu/kermit/utf8.html
http://www.cl.cam.ac.uk/~mgk25/ucs/examples/UTF-8-test.txt
We can compare decoders of Chrome and Opera browsers on an example of a test page (http://www.cl.cam.ac.uk/~mgk25/ucs/examples/UTF-8-demo.txt):
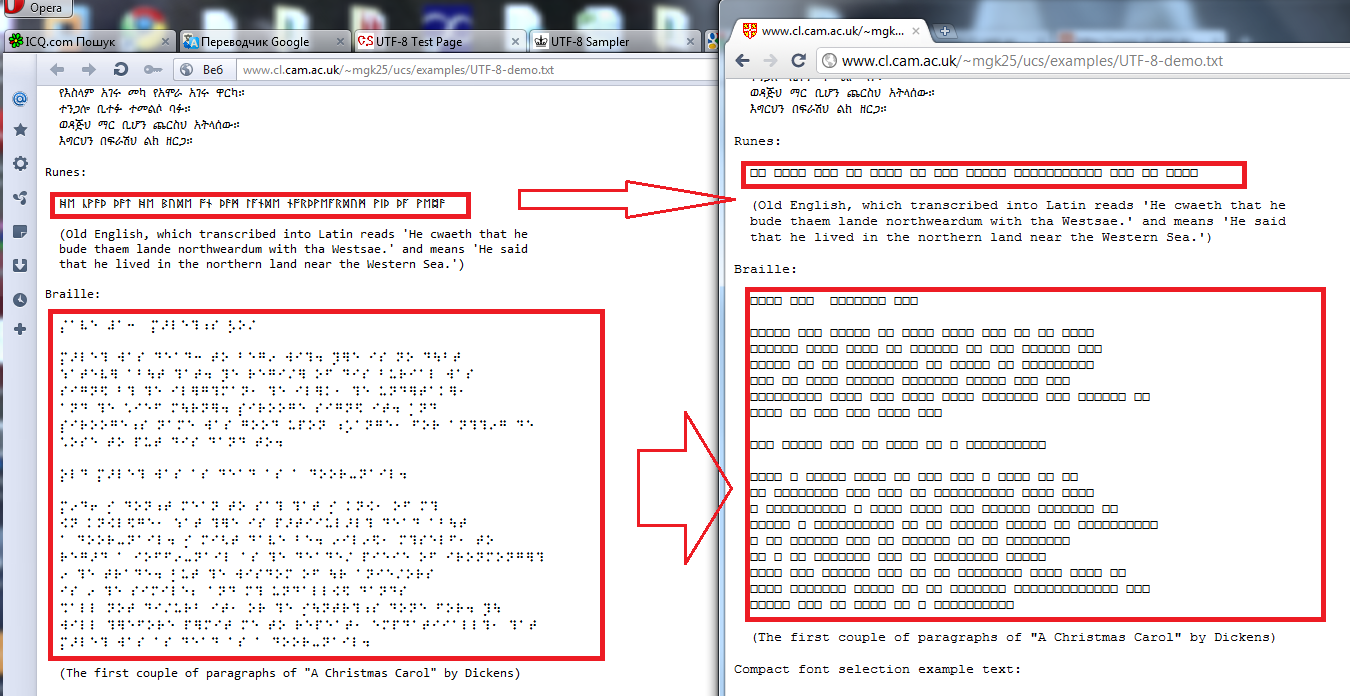
Fig.8. Incorrect decoding of Runes and Braille in Chrome
If there are □ � symbols in the text, this means that the code combination is not recognized.
As it was mentioned above, it can be forcibly defined in the HTML tag body in which encoding the text will be. For testing of the correct work, you will need to create html documents with explicit and inexplicit definition of encodings. To do this, open the ready document in Notepad and search for the following:
Explicit method:
<META Name=”Content-Type” Value=”text/html;charset=utf-8″>
Inexplicit method:
<META Name=”Content-Type” Value=”text/html “>
Special attention should be paid to programs that work with data decoding. Here, there can hide a number of bugs taking into account the possibility of dual representation of symbols in UTF-8, 16.
Checklist of testing of a program for Unicode decoding will look as follows:
Table 2. Checklist for Unicode testing
|
|
ASCII |
Left-to-right |
Right-to-left |
Bi-direct |
Vertical |
Surrogate |
|
UTF-8 |
+ |
+ |
+ |
+ |
+ |
– |
|
UTF-16 LE |
+ |
+ |
+ |
+ |
+ |
+ |
|
UTF-16 BE |
+ |
+ |
+ |
+ |
+ |
+ |
|
UTF-32 LE |
+ |
+ |
+ |
+ |
+ |
– |
|
UTF-32 BE |
+ |
+ |
+ |
+ |
+ |
– |
+ -possible combination
– -impossible combination
In the column to the left, Unicode formats are located; in the top row, the text contents are located. On their crossing, we receive combinations of bidirectional writing in UTF-16LE, ASCI text in UTF-32BE. Such data can be created with the help of the UniPad program described in chapter 5.
Program Tools for Creation of Test Data
Creation of test data on the basis of a number of languages and symbols is the necessary task when testing programs that decode and transform input data. A lot of programs are developed to help with these tasks:
1. UniPad, Sharmahd Computing – program is a multi-language notepad. The full version of the program is not free of charge but you can download a free temporary version on the manufacturer site (available for downloading at http://www.unipad.org/download/).
With its help, you can create text document in all languages supported in Unicode 4.1. There is a possibility of creation of surrogate pairs. All known diacritical symbols are available. Bidirectional writing is also available. And as a result, you can save all this in any Unicode format. Also, you can analyze existing documents. Drawing of complex symbols both in the form of a picture and stacking from more simple symbols is possible.
An example of creation of a text file with an Arabic writing with a right-to-left direction, bidirectional writing (English and Arabic text), and Hindi writing with surrogate pairs:
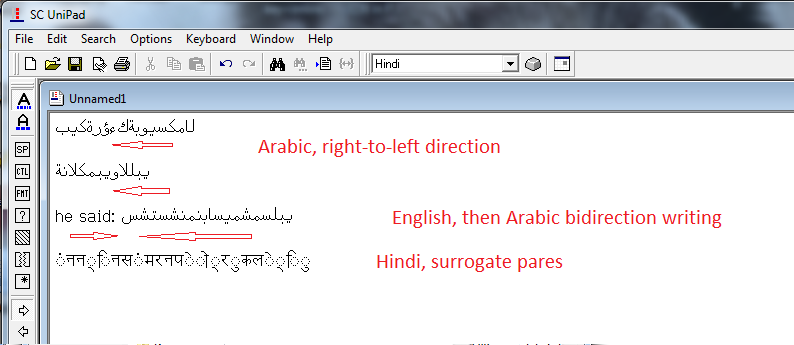
Fig.9. Example of creation of a text file
If we save the text in all Unicode formats, we will receive the cover of a checklist table presented in chapter 4.
2. AkelPad is a free application (available for download at official site http://akelpad.sourceforge.net/ru/download.php).
It represents a notepad with enhanced possibilities. Unlike the previous program, it does not work with Unicode so well. When opening the test page in UTF-8, it is recognized as UTF-16LE and some symbols are not displayed. But it has a wide range of encodings for saving. With its help, you can convert texts from universal encodings to the national ones and vice versa.
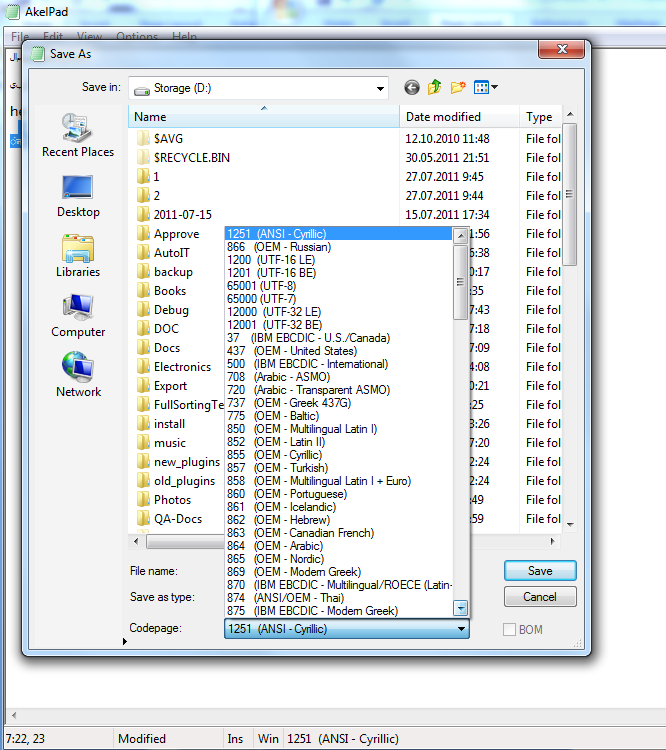
Fig.10. List of encodings available for saving
We hope that this article will help you in your work!
Check out other QA blog posts – learn What is impact analysis.
Read also:


