 Skip to main content
Skip to main content
Businesses put lots of effort into making their digital products smart, convenient, and functional. However, all this effort goes to waste if a product is simply not available.
For digital products, each second of downtime can result in significant financial losses, reputational damage, and loss of customers to competitors with more reliable systems. That’s why it’s crucial to ensure fault tolerance — the ability of software to stay live despite hardware failures, bugs, or network issues.
In this article, you’ll learn how to use chaos testing to provide uninterrupted service to your customers and increase your product’s resilience. This article will be useful for product leaders who want to improve their product’s reliability and stability with chaos testing.
Contents:
What is chaos testing and why should you use it?
Since the beginning of the internet, software failures have plagued nearly every company. In the past decade alone, network disruptions have cost even leading organizations dearly. Google has experienced costly downtime multiple times.
The fundamental rule of fault tolerance is also known as Murphy’s Law: anything that can go wrong will go wrong. However, if something does go wrong, it shouldn’t lead to failure of the entire system. To ensure software resilience, it’s necessary to simulate failures and mitigate their negative impacts before real users are affected. This is exactly what chaos testing is for.
What is chaos testing?
Chaos testing is a relatively new method of software testing that allows developers to determine and forecast system behavior in the event of a system failure, network interruption, or hardware-related issue. It involves using unexpected and random failure conditions to identify system bottlenecks, vulnerabilities, and weaknesses. Chaos testing is an important part of creating and maintaining fault-tolerant applications.
When executed in a controlled manner, chaos testing is effective at preparing for, minimizing, and preventing disruption and downtime before they occur. Often, quality assurance (QA engineers) use stress testing to deliberately cause a system failure to see how the application copes.
Who performs chaos testing?
In larger projects, QA specialists predominantly handle chaos testing, but in some cases, you may want to form a dedicated team. Such a team typically includes QA, DevOps, and software development specialists. In existing projects where chaos testing has not previously been applied, you can still perform it during technical audits to identify potential points of failure and enhance the product’s reliability.
Why conduct chaos testing?
Let’s talk about the main benefits you can get by integrating chaos testing into your software development routine.
- Enhanced system resilience. By deliberately inducing failures, chaos testing enables organizations to assess how their systems respond under adverse conditions. By identifying weaknesses and vulnerabilities, they can implement targeted improvements to enhance overall system resilience.
- Improved data security. Chaos testing helps uncover potential weaknesses in data handling processes and security measures. By simulating various failure scenarios, organizations can identify and address vulnerabilities, ensuring the security and integrity of sensitive data even during system failures.
- Preservation of reputation. Proactively testing system resilience through chaos testing helps prevent unexpected downtime and service disruptions. By ensuring uninterrupted service, organizations maintain customer trust and confidence, safeguarding their reputation and competitiveness.
- Promotion of innovation. Chaos testing provides valuable insights into system behavior and performance under stress. By analyzing test results, teams can identify areas for improvement and innovation, driving continuous enhancement of software products and services.
Now, let’s discuss the concrete goals you can achieve with chaos testing.
Keep your system working anytime, under any circumstances
Get a team of skilled engineers and QA specialists by your side. Apriorit professionals will ensure your product’s reliability and uninterrupted work!
Goals of chaos testing
Before introducing any practice to your software development process, it’s crucial to clearly define the goals you expect to achieve. This allows your managers and engineers to plan the workflow accordingly. Below, we list the four most important goals that chaos testing can help businesses achieve.
Identify system weaknesses. One of the primary goals of chaos testing is to proactively uncover hidden weaknesses within a system. While traditional testing methods focus on expected behavior, chaos testing aims to expose vulnerabilities. To do this, chaos testers deliberately introduce disruptions like network failures or resource shortages that allow them to identify issues like inadequate error handling or resource allocation bottlenecks.
Predict and prevent failures. A unique aspect of chaos testing is its focus on preventive measures. By predicting issues before they occur and implementing preventive measures, organizations can reduce the potential impact of failures. Chaos experiments help predict how the system may behave under various conditions and address issues before they affect users.
Minimize downtime. Chaos testing aims to minimize downtime by identifying potential failure points and implementing strategies to mitigate their impact. For example, at Apriorit, we simulate server outages or network disruptions to evaluate a system’s recovery speed. This helps us fine-tune recovery mechanisms, implement load balancing, and optimize infrastructure to minimize downtime.
Improve the user experience. Chaos testing enhances the overall user experience by identifying and addressing issues that may impact users. A key goal is to ensure smooth and uninterrupted user interactions with the system, even under stress. By monitoring user interactions, organizations can identify and resolve issues, such as by optimizing response times, improving error handling, and ensuring the availability of critical functions for users, even during failures such as system failures, network interruptions, or service degradation.
When developing software products, we focus on a system’s scalability. If we anticipate an increase in service load over time, our engineers simulate such scenarios in advance to optimize the system accordingly. This allows us to address issues before they arise, help our clients avoid additional costs, and prepare the system for potential loads.
Related project
Improving a SaaS Cybersecurity Platform with Competitive Features and Quality Maintenance
Discover how the Apriorit team helped to improve a SaaS cybersecurity platform with new functionality that made it more stable, resilient, and competitive.

When to perform chaos testing
There is a common belief that chaos testing should be introduced as early as possible, especially for products with microservices architectures due to their extensive infrastructure and dependencies. This is only partially true.
Let’s look at the main cases when chaos testing is advisable:
- You have a relatively large product that must operate 24/7 regardless of circumstances, with every minute of downtime threatening customer and revenue loss.
- You’ve introduced changes to the infrastructure or added new functionality. In this case, it’s a good idea to perform high-level chaos testing.
- Your product started out relatively simple, but with time it has scaled significantly. In this case, even if it has a monolithic architecture, chaos testing is still necessary.
Chaos testing is not a basic and mandatory part of testing, but it varies from case to case and can be introduced at any stage of your development lifecycle.
At Apriorit, we tailor our chaos testing recommendations to suit each project’s specific needs and stages. For instance, when our client is in the initial stages of creating an MVP, we typically advise against implementing chaos testing due to the primary focus on delivering essential features within tight budgets and time constraints. While valuable for enhancing system resilience, chaos testing can introduce unnecessary complexity and overhead during an MVP’s rapid development and deployment phase.
At the MVP stage, we prioritize building core functionality and ensuring a stable foundation for the product before considering advanced testing methodologies like chaos testing.
However, when the product grows and it becomes apparent that stability and reliability are crucial, we suggest chaos testing as a separate activity.
How to do chaos testing right: Apriorit’s take
All the perks of chaos testing, like safeguarding your product against failure and downtime, can be yours if done regularly and correctly. At Apriorit, we’ve navigated countless pitfalls and unexpected twists over the years, refining our process along the way. Below, we provide a brief overview of our workflow and a step-by-step guide, outlining key nuances to be aware of.
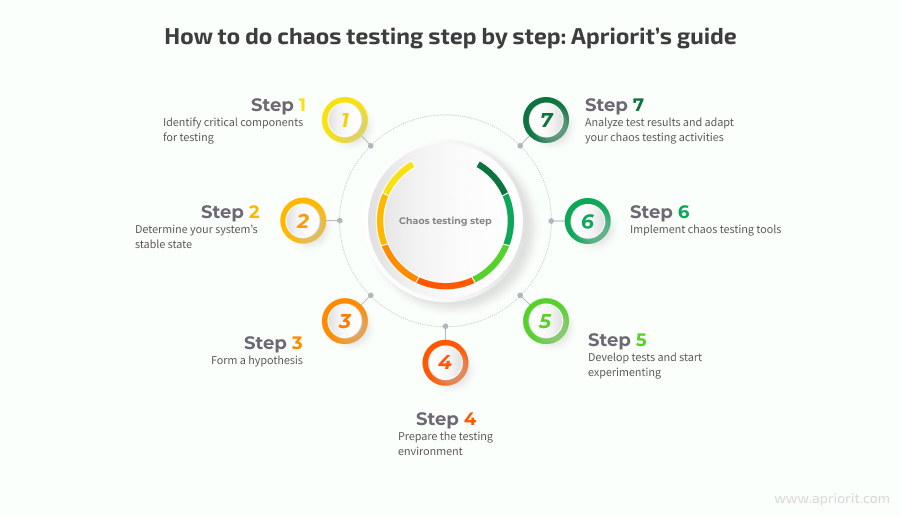
Step 1. Identify critical components for testing
The first thing we do at Apriorit when implementing chaos testing is to identify the parts of the system or application that are most critical to the business. These are the components that would have the most significant negative impact on the business in case of total or partial failure.
For example, the system’s performance and ability to quickly handle customer requests, especially during periods of increased demand (peak load), are extremely important for e-commerce products. On the other hand, security and data confidentiality are paramount for products involving interaction with individuals and companies and handling personal data (such as CRM systems, LMS systems, or FinTech apps).
To identify critical components, we collaborate closely with the client to understand their business objectives, user requirements, and specific functionalities that are vital for the success of their application or system.
Step 2. Determine your system’s stable state
The next step is determining the system’s stable state. A stable state is a set of parameters that align with the expected and predictable behavior of the system over time.
To determine a system’s stable state, we first define a set of metrics that align with expected experimental outcomes. Usually, we use business metrics, such as user engagement indicators like orders per minute or user registrations, as they directly reflect the user interaction. However, it’s important to monitor the overall state of the system and consider other metrics like request rates or CPU load.
Also, if we have previously identified weak points during overall quality assurance testing or audits, we start our testing process by addressing them first.
For large systems, we may add another step and divide the whole system into manageable parts. The process can look like this:
- Identify a segment of the system (such as specific functionality) to test.
- Determine the stable state for that segment.
- Compile a list of infrastructure elements necessary to support its stable operation (databases, specific microservices, load balancers, etc.).
This approach provides us with a better understanding of the system and allows for more targeted testing.
Read also
AWS Auto Scaling Strategies for High-Load Systems: AWS Scale Service Comparison
Build a flexible system to handle unpredictable loads. Discover our guide to autoscaling strategies and choose the perfect one for your product!

Step 3. Form a hypothesis
The next step is forming a testable hypothesis. It should look something like this: “There will be no changes in the steady state when X is introduced into the system.”
The most effective experiments may lead to loss of availability of one or more system components. Types of testing may include:
- Hardware failure (or its virtual equivalent)
- Changes in network latency
- Network failure
- Resource starvation/overload
- Dependency failures (such as in databases)
- Functional errors (exception handling)
- Increased load conditions (multithreading requests)
Each chaos testing team should identify critical components for which they are responsible and focus on ensuring expected availability under adverse conditions. This could involve unforeseen network delays, lost data packets, memory or CPU overload, time zone mismatches between users and the application, or any number of other parameters.
Typically, we find that components responsible for managing and storing system state data have the greatest impact on overall system availability. Once we achieve the resilience of these systems, we move on to testing other less critical systems.
Step 4. Prepare the testing environment
Until the system is highly trusted, we conduct chaos testing experiments solely in a test environment. Once the system is reliable enough, we can carry out chaos testing in real-world (production) conditions, or as close to real-world conditions as possible.
It’s crucial to aim for conducting chaos engineering experiments in the production environment, even if you don’t plan to do them regularly. One of the most critical aspects of chaos testing is ensuring excellent user experience even when unexpected events occur. While chaos testing can simulate unexpected events in a test environment, true validation can only occur within the production system.
Additionally, chaos testing scenarios should be reproducible. For this, we establish a team-owned space like a repository where we can replicate tests as regularly as our testing plan requires and repeat them for new system components.
Read also
How We Scaled API Performance in a High-Load System and Avoided CPU Overload
Learn how to scale your API for optimal performance. Explore our practical guide for expert insights and strategies to keep your system running smoothly, even under heavy loads.

Step 5. Develop tests and start experimenting
A hypothesis is essentially a nearly ready-made test scenario. Apriorit engineers format it into a series of tests, typically focusing on high-level tests that examine the overall behavior or performance of the system without delving into detailed technical aspects.
These tests simulate failures in hardware, virtual machines, or Kubernetes modules. The aim is to understand how infrastructure and application components respond to deliberate chaotic events to ensure uninterrupted operation or minimize negative consequences in case of unforeseen issues.
It’s worth noting that chaos tests often go beyond simple pass/fail outcomes. The goal is to understand the system and build resilience to any issue, not just a specific scenario. Chaos testing isn’t suitable for continuous integration / continuous development (CI/CD) level testing; it’s not like standard unit or integration testing, which can be automated. Instead, it’s more about helping those building and operating software systems to understand system behavior and validate assumptions.
While it may seem similar to conventional testing at first glance, chaos testing is fundamentally different. Unit tests and integration tests are based on knowns and unknowns, but one of the values of chaos testing lies in discovering unknowns. In this sense, it’s closer to an experiment focused on discovery and understanding rather than pass/fail testing. Consequently, chaos tests should be specific exercises regularly performed by the team to ensure a high level of fault tolerance and system confidence.
Once the tests are prepared, we begin testing while observing the system. If the system responds as expected, the test is considered successful. Unexpected behavior or any significant negative impact on the system indicates an unsuccessful test (although, for the team, this is a significant win because they now have a better understanding of the system!). We need a deep understanding of the actions causing the failure to be able to rerun the test after making system improvements until achieving a successful outcome.
Pro tip: There will be times when it’s necessary to put the system in a specific state, making it vulnerable to failure: for example, increasing CPU or memory load or changing network delays to simulate rare situations. We usually achieve this through external load profiling or by adding artificial processes to the system. This helps us uncover some hard-to-detect issues that may pose debugging challenges.
Teams must master the skill of crafting chaos scenarios, fostering a deep understanding of the system and how it responds to unexpected changes. This experience helps in designing systems and developing applications inherently resilient to failure. Therefore, it’s critical for development teams to take responsibility not only for testing but, ideally, also for operating systems to establish close collaboration. Critical system issues may be overlooked if only the testing team is responsible for chaos testing and scenario development.
Building a Microservices SaaS Solution for Property Management
Related project
Explore how Apriorit’s experts helped our client attract new customers, optimize costs, and ease new feature implementation by replacing their monolithic solution with a flexible microservice-based SaaS platform.

Step 6. Implement chaos testing tools
Apriorit QA engineers regularly use time-proven tools to conduct various chaos tests. These tools allow us to partially automate and structure the testing process. Let’s take a look at some of the chaos testing software we use for best results:

Chaos Mesh
Chaos Mesh is a chaos engineering solution designed specifically for Kubernetes environments. It introduces faults at every level of the Kubernetes system, allowing users to simulate various failure scenarios, such as pod deletions, network disruptions, or read/write errors.
Key features:
- Easy deployment on Kubernetes clusters without altering deployment logic
- Integration into CI/CD processes for automation
- No unique dependencies required for deployment
- Custom chaos objects defined using CustomResourceDefinitions (CRD)
- Dashboard for tracking experiment analytics
Pumba
Pumba is an open-source chaos testing tool tailored for Docker containers. It enables intentional disruptions of Docker containers running applications to observe system behavior. Pumba can also perform stress testing on container resources, including CPU, memory, file system, and I/O.
Key features:
- Simple configuration for Docker container use
- Selective targeting of specific or random Docker containers for faults
- Network emulation for simulating various network failures
Gremlin
Gremlin is a Software as a Service (SaaS) platform that helps engineers build more resilient software by conducting chaos engineering experiments. It offers multiple types of attacks to test system resilience and allows users to customize scenarios based on system data. Gremlin supports testing across various cloud providers and on-premises environments. Users can inject chaos into hosts or containers regardless of their location, whether in a public cloud or a private data center.
Key features:
- Integration with CI/CD pipelines
- Granular control over chaos injection
- Support for microservices architectures
- Integration with monitoring and alerting systems
- Comprehensive reporting and analysis
- Support for compliance and security standards
- API support for manual integrations
Chaos Monkey
Chaos Monkey is a pioneering chaos testing tool that intentionally introduces failures to assess the resilience of cloud-based systems. It randomly terminates virtual machine instances and containers to evaluate system reliability and fault tolerance.
Key features:
- Easy tracking and scheduling of attacks
- Open-source software with no licensing costs
- Extensive history of development and refinement
Step 7. Analyze test results and adapt your chaos testing activities
After completing chaos testing, we carefully analyze the results. This involves assessing whether the expected outcomes were achieved. If any experiments fail to meet expectations, our team conducts a thorough analysis to understand the reasons behind the discrepancies.
This analysis often involves using available monitoring tools such as logging, metrics, and system tracing. Chaos engineering is not solely the responsibility of testers; it requires a collaborative effort from the entire team to effectively identify and address root causes.
Once root causes have been identified, they need to be addressed promptly. This may involve making improvements to monitoring tools or adapting tests accordingly. In some cases, it might be necessary to reassess the initial hypothesis and refine tests for retesting.
At Apriorit, we continue to conduct tests, analyze results, and make improvements until we achieve the desired outcomes and the system is stable, even under pressure.
Read also
Reducing the Load on the QA Team and Improving Product Quality with Cypress Automation Testing
Reduce your QA team’s manual labor without sacrificing the quality of your product! Discover our practical guide to test automation with Cypress and make your QA faster and more efficient!

How Apriorit can help you with chaos testing
At Apriorit, we bring extensive experience in chaos testing and a deep commitment to our client’s business success. Our goal is to ensure that our clients’ systems perform flawlessly under any circumstances, safeguarding client reputations and customer trust.
By partnering with Apriorit, you get:
- A team of seasoned specialists who understand firsthand what pitfalls and challenges can arise during chaos testing. We have learned valuable lessons along the way, allowing us to navigate complex testing scenarios with confidence and precision.
- Secure solutions, as we are a security-first company and our specialists prioritize cybersecurity at every step of the testing process, ensuring that our clients’ systems and data remain safe and protected from potential threats.
- Inherent fault tolerance and uninterrupted service. We go beyond addressing individual failure points for clients seeking to build truly resilient systems. We advocate for a distributed architecture, where backup components automatically replace failed ones, ensuring uninterrupted operation.
Let’s explore a few real-life chaos testing examples that demonstrate how we tailor individual strategies for our clients’ products:
- Checking interactions between the product and the database. In one of our projects, we had to focus on testing interactions between the product and the database. The goal was to protect our client’s sensitive data. By simulating scenarios where database performance is degraded or the volume of database queries significantly increases, we can assess how well the application handles such situations. We always aim to prevent data loss or leakage, ensuring the integrity and confidentiality of user information.
- SMTP server testing. Another example involves testing SMTP server functionality, particularly for applications that send email notifications to users. In addition to basic functionality checks, we can conduct stress tests to evaluate the system’s behavior when sending mass emails or when the SMTP server is unavailable. In one of our projects, we identified an issue where a portion of email messages failed to reach recipients during mass sends due to exceeding the SMTP server’s throughput capacity. By analyzing the root cause, we were able to refine the solution and eliminate the problem.
Partnering with Apriorit for chaos testing means gaining access to experts who prioritize your business objectives, security, and resilience. We leverage our expertise and real-world examples to craft customized chaos testing strategies that fortify your systems against potential failures and security threats, setting the stage for long-term success.
Conclusion
Fault tolerance is one of the most important qualities of a reliable, stable, and user-friendly system. It directly affects your business by ensuring continuous operation, minimizing downtime, and maintaining customer satisfaction.
Chaos testing plays a vital role in achieving fault tolerance by proactively identifying weaknesses and vulnerabilities within your system. By subjecting your application to controlled chaos, you can uncover potential failure points and address them before they impact your users. This proactive approach not only enhances system reliability but also instills confidence in your product’s performance under adverse conditions.
At Apriorit, we understand the critical importance of fault tolerance and the role chaos testing plays in achieving it. Partner with our QA team and leverage our deep domain knowledge, robust methodologies, and advanced testing techniques to fortify your systems against potential failures and security threats.
Ready to enhance your application’s resilience?
Reach out to us now for expert assistance in quality assurance and drive your system’s reliability!
Have a question?
Ask our expert!
VP of Engineering


